

داده کاوی (Data Mining) از داده های خام برای استخراج اطلاعات یا در واقع استخراج اطلاعات مورد نیاز از داده ها استفاده می کنند. Data Mining در متنوع ترین برنامه ها از جمله پیش بینی مدل سیاسی ، پیش بینی مدل الگوی هوا ، پیش بینی رتبه بندی وب سایت و غیره مورد استفاده قرار می گیرد. داده کاوی همچنین در سازمان هایی که از داده های بزرگ به عنوان منبع داده خام خود برای استخراج داده های مورد استفاده می شود.
برای خرید لایسنس Tableau کلیک کنید
تکنیک های مورد استفاده در داده کاوی
حالت داده کاوی با استفاده از الگوریتم بالای داده های خام ایجاد می شود. مدل استخراج بیش از الگوریتم یا متادیتا است. این مجموعه ای از داده ها ، الگوها ، آمارها است که می تواند در داده های جدیدی که برای تولید پیش بینی ها و دریافت برخی استنتاج ها در مورد روابط ارائه می شوند ، قابل استفاده باشد.
موارد زیر برخی از تکنیک هایی است که در داده کاوی استفاده می شود.

-
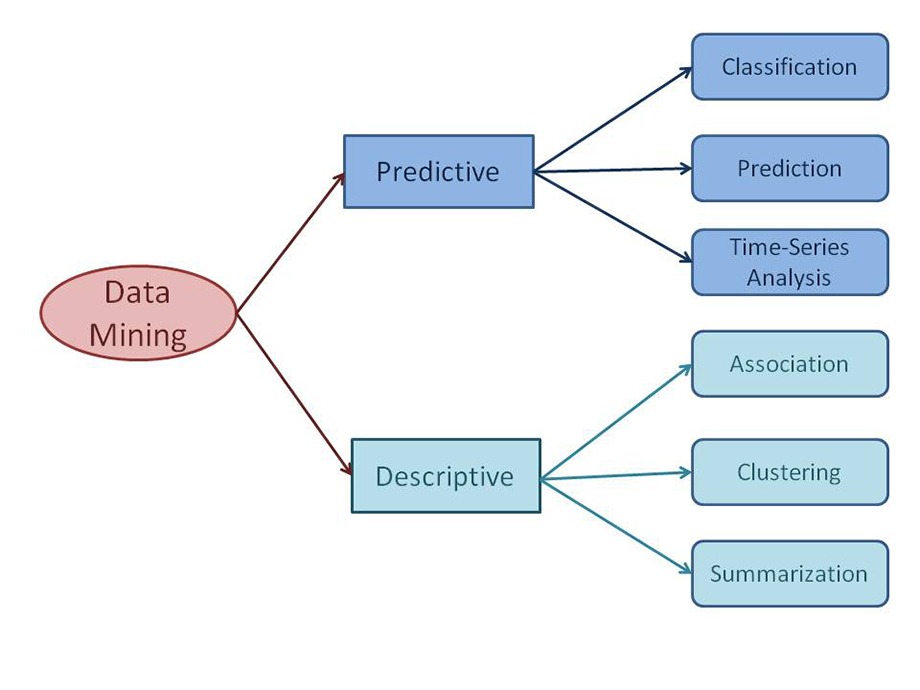
تکنیک توصیف داده کاوی (Descriptive Data Mining Technique)
این روش به طور کلی برای تولید جدول بندی متقابل ، همبستگی ، فراوانی و غیره داده می شود. این روش های توصیف داده کاوی برای بدست آوردن اطلاعات مربوط به قاعده بودن داده ها با استفاده از داده های خام به عنوان ورودی و کشف الگوهای مهم استفاده می شود. کاربرد دیگر این درک گروههای فریبنده ( captivating groups ) در منطقه وسیعتر داده های خام است.
-
تکنیک پیش بینی داده کاوی (Predictive Data Mining Technique)
هدف اصلی روش پیش بینی استخراج ، شناسایی نتایج آینده نگرانه به جای تمایل فعلی است. توابع بسیاری برای پیش بینی مقدار هدف استفاده می شود. تکنیک هایی که در این گروه قرار می گیرند ، طبقه بندی ، رگرسیون و تحلیل سری زمانی هستند. مدل سازی داده ها یک اجبار برای این تجزیه و تحلیل پیش بینی است ، که با استفاده از برخی متغیرها داده های آینده نگرفته را برای سایر متغیرها پیش بینی می کند.
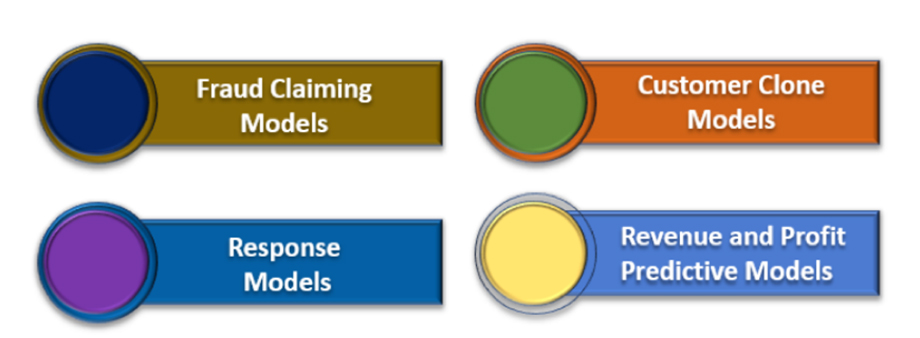
انواع مدل ها در داده کاوی
چند مدل داده کاوی که شرح داده شده است:
-
مدل های تقلب ( Fraud Claiming Models )
تقلب چالشی است که بسیاری از صنایع و به ویژه صنعت بیمه با آن روبرو هستند. این صنایع باید دائماً با استفاده از داده های خام پیش بینی کنند تا ادعاهای کلاهبرداری قابل درک و عمل باشد. ما می توانیم ادعاهایی را که به صورت داده های خام وارد می شوند ردیابی کنیم و احتمال کلاهبرداری آنها را شناسایی کرده و در نتیجه پس انداز زیادی برای شرکت بیمه انجام دهیم.
-
مدل های Clone مشتری
مدل شبیه سازی مشتری می تواند بر اساس ویژگی های “بهترین مشتریان” سازمان ، پیش بینی کند و نمایش دهد.
-
مدل های پاسخ ( Response Models )
مدلهای پاسخ پیش بینی داده کاوی به سازمانها کمک می کند تا الگوهای استفاده را که پایگاه مشتری آنها را تفکیک می کند شناسایی کنند تا با آن مشتریان تماس بگیرند. این مدل پاسخ بهترین روش برای پیش بینی و شناسایی مشتری یا چشم انداز مشتری مداری برای هدف برای یک محصول خاص است. این پیشنهاد با استفاده از مدل توسعه یافته مطابقت دارد. این مدل ها در شناسایی مشتریانی که به احتمال زیاد ویژگی هدف قرار گرفتن را دارند ، به کار می روند.
-
مدل های پیش بینی درآمد و سود ( Revenue and Profit Predictive Models )
مدل های پیش بینی سود و سود ، ویژگی های پاسخ یا عدم پاسخ را با برآورد درآمد مشخص ترکیب می کنند ، به خصوص اگر اندازه های سفارش داده شده ، حاشیه ها به طور گسترده یا صورتحساب ماهانه متفاوت باشد.
همانطور که می دانیم ، همه پاسخ ها دارای ارزش یکسان یا یکسان نیستند و الگویی که می تواند پاسخ ها را افزایش دهد ، لزوماً سود ما را به دست نمی آورد. درآمد و تکنیک پیش بینی سود نشان می دهد که آن دسته از پاسخ دهندگانی که به احتمال زیاد با پاسخ خود نسبت به سایر پاسخ دهندگان ، حاشیه سود یا سود را افزایش می دهند.
اینها برخی از انواع مدل هستند و موارد دیگری وجود دارد که می تواند به جمع آوری داده های مورد نیاز از مجموعه داده های خام کمک کند.
الگوریتم های داده کاوی ( Data Mining Algorithms )
بسیاری از الگوریتم های داده کاوی وجود دارد. ما در اینجا درباره چند مورد بحث خواهیم کرد. بیایید ببینیم که چرا برای استخراج داده ها به الگوریتم نیاز داریم. در دنیای امروز ، که تولید داده بسیار زیاد است و داده های بزرگ کاملاً رایج است ، ما باید الگوریتمی داشته باشیم که برای پیش بینی الگو و تجزیه و تحلیل ، باید روی آنها اعمال شود.
ما الگوریتم های مختلفی مبتنی بر مدل استخراج داریم که می خواهیم روی داده های خود اعمال کنیم. برخی از آنها در زیر آورده شده است:

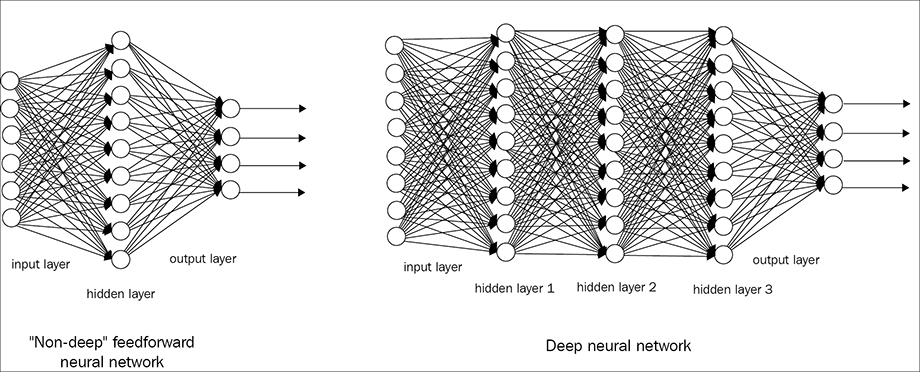
۱- الگوریتم ANN ( ANN Algorithm )
این الگوریتم ANN از شبکه های عصبی بیولوژیکی الهام گرفته شده است و مانند معماری رایج رایانه است. این الگوریتم برای بدست آوردن الگویی از توابع تقریب در تعداد زیادی داده نامشخص استفاده می کند. آنها به طور کلی به عنوان سیستمی از نورون های بهم پیوسته نشان داده می شوند که می توانند برای تأمین خروجی محاسبه را وارد و انجام دهند.
۲-الگوریتم ساده لوح بیز ( Naive Bayes Algorithm )
الگوریتم Naive Bayes براساس قضیه Bayesian بنا شده است و این الگوریتم زمانی استفاده می شود که ابعاد داده ها بالاتر باشد. طبقه بندی Bayesian قادر است با وارد کردن داده های خام ، خروجی احتمالی ایجاد کند.
در اینجا همچنین امکان افزودن داده های خام جدید در زمان اجرا و دریافت پیش بینی ها وجود دارد. یک طبقه بندی Bayes قبل از خروجی ، همه احتمالات را در نظر می گیرد.
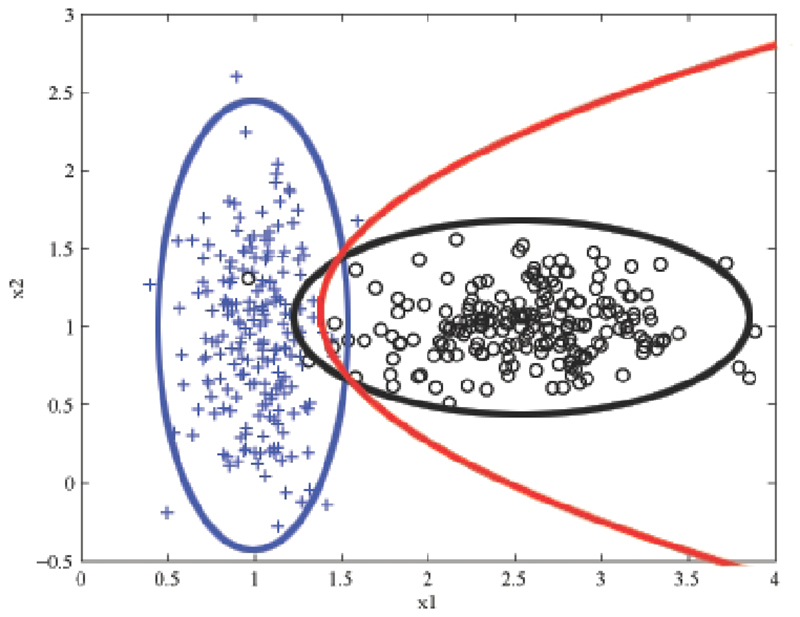
۳- الگوریتم SVM ( SVM Algorithm )
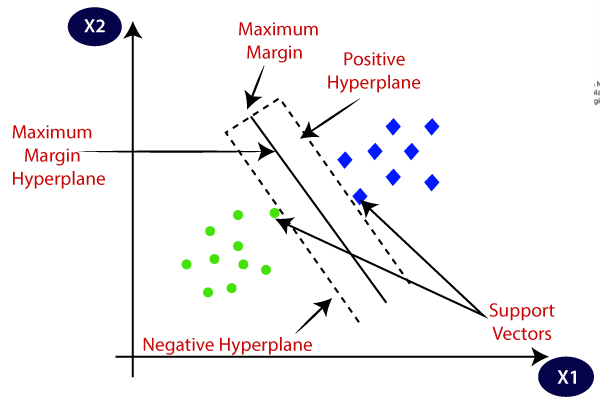
این الگوریتم SVM در دهه گذشته مورد توجه بسیاری قرار گرفته است و در گسترده ترین برنامه کاربردی اعمال می شود. الگوریتم SVM بر اساس تئوری یادگیری آماری و اصل ارزیابی ریسک ساختاری و به حداقل رساندن آن است. این می تواند مرزهای تصمیم گیری را شناسایی کند و همچنین یک ابر هواپیما نامیده می شود که می تواند جدایی بهینه از کلاس ها را ایجاد کند و در نتیجه بیشترین فاصله ممکن را بین ابر هواپیمای تفکیک شده ایجاد کند. SVM قوی ترین و دقیق ترین روش طبقه بندی است اما وقت گیر است.
مزایای مدل های داده کاوی
مزایای بسیاری در مدل های داده کاوی وجود دارد و برخی از آنها در زیر ذکر شده است:
- این مدل ها به سازمان کمک می کنند تا الگوی خرید مشتری را شناسایی کند و سپس اقدامات مناسبی را که می توان برای افزایش درآمد انجام داد پیشنهاد می کند.
- این مدل ها می توانند به ما کمک کنند تا بهینه سازی وب سایت را افزایش دهیم تا مشتری بتواند به راحتی موارد مورد نیاز را کشف کند.
- این مدل ها به ما کمک می کنند تا کمپین های بازاریابی را در زمینه و روش های مطلوب شناسایی کنیم.
- به ما کمک می کند که مشتری و نیازهای او را شناسایی کنیم تا محصولات مورد نیاز تأمین شود.
- به افزایش وفاداری به برند کمک می کند.
- به اندازه گیری سودآوری عوامل افزایش درآمد کمک می کند.
نتیجه گیری
بنابراین ما تعریف داده کاوی و چرایی آن را مشاهده کرده ایم و تفاوت بین مدل توصیفی و پیش بینی داده همسویی را درک کرده ایم. همچنین ، ما برخی از مدل های داده یابی و چند الگوریتم را دیده ایم که به سازمان کمک می کند بینش بهتری نسبت به داده های خام داشته باشد.
دوره آموزشی هوش تجاری با Tableau »کلیک کنید« و هوش تجاری با Power BI »کلیک کنید« یک برنامه جامع است که بر توسعه مهارت در تجزیه و تحلیل دادهها، تجسم و گزارش سازی و گزارش دهی و دشبوردسازی با استفاده از این ابزارها تمرکز دارد.
سپاسگذاریم از وقتی که برای خواندن این مقاله گذاشتید
.
برای خرید لایسنس پاور بی ای Power BI کلیک کنید
.
برای مشاهده ویدیوهای آموزشی داده کاوی و هوش تجاری ما را در شبکه های اجتماعی دنبال کنید
Youtube Chanel :VISTA Data Mining ![]()
Aparat Chanel: VISTA Data Mining ![]()
Instagram Chanel: VISTA Data Mining ![]()
Telegram Chanel: VISTA Data Mining ![]()
Linkedin Chanel: VISTA Company ![]()






