


data mining with rapidminer
داده کاوی چیست؟
داده کاوی فرآیند یافتن الگوها و دانش جالب از مقادیر زیاد داده است.منابع داده شامل پایگاه های داده، انبارهای داده، وب و سایر مخازن اطلاعات یا داده هایی هستند که به صورت پویا به سیستم جریان می یابند. این تحلیل برای فرآیند تصمیم گیری انجام می شود.
داده کاوی برای پردازش داده هایی استفاده می شود که در ابتدا معنایی به اطلاعات ندارند و سپس اطلاعات به دانش تبدیل می شوند. داده کاوی، همچنین به عنوان کشف دانش در پایگاه های داده شناخته می شود.
چندین روش یا وظایف داده کاوی را می توان برای یافتن، تجزیه و تحلیل، کاوش و استخراج دانش استفاده کرد. 5 وظیفه اصلی وجود دارد :
- تخمین
- پیش بینی
- طبقه بندی
- خوشه بندی
- ارتباط
پلتفرم های توسعه بدون کد چیست؟
Python و R محبوب ترین زبان های برنامه نویسی برای داده کاوی در حال حاضر هستند.
اما اگر زمان کمی دارید یا واقعاً با پایتون آشنایی ندارید، می توانید از پلتفرم های توسعه بدون کد استفاده کنید.
یک پلت فرم توسعه بدون کد ما را قادر می سازد تا وظایف داده کاوی را با کشیدن و رها کردن انجام دهیم.همچنین ما را قادر می سازد تا پروژه های داده کاوی را به سرعت بدون کدنویسی توسعه دهیم.توسعه دهندگان و غیر توسعه دهندگان می توانند از این ابزارها برای تمرین توسعه سریع داده کاوی با گردش کار و عملکرد سفارشی شده استفاده کنند.
Rapidminer چیست؟
رپیدماینر یک پلت فرم جامع علم داده با طراحی گردش کار بصری و اتوماسیون کامل است.این بدان معناست که ما نیازی به کدنویسی برای وظایف داده کاوی نداریم.
رپیدماینر یکی از محبوب ترین ابزارهای علم داده است.این رابط کاربری گرافیکی فرآیند خالی در rapidminer است.
دارای مخزنی است که مجموعه داده ما را نگه می دارد. ما می توانیم مجموعه داده های خود را وارد کنیم.همچنین مجموعه داده های عمومی زیادی را ارائه می دهد که می توانیم آنها را امتحان کنیم.ما همچنین می توانیم با اتصال پایگاه داده کار کنیم.در زیر پنجره مخزن، یک اپراتور دارد.
اپراتورها شامل همه چیزهایی هستند که برای ایجاد یک فرآیند داده کاوی نیاز داریم، مانند دسترسی به داده، پاکسازی داده ها، مدل سازی، اعتبارسنجی و امتیازدهی.
در سمت راست پنجره پارامترها قرار دارد. پنجره پارامترها برای تنظیم عملگرها است.
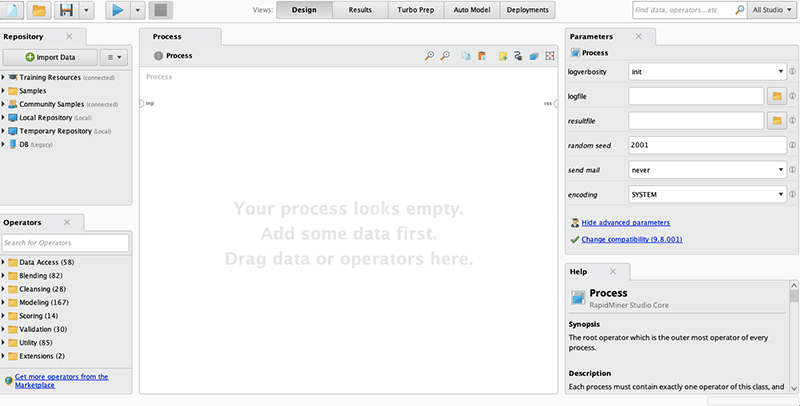
Rapidminer را می توان از وب سایت رسمی آنها (https://rapidminer.com) دانلود کرد. این یک نسخه رایگان با عملکرد محدود است. نسخه رایگان شامل 10000 ردیف داده و 1 پردازشگر منطقی است.
آنها همچنین یک برنامه آموزشی ارائه می دهند. به طوری که دانشجویان، اساتید، مربیان و پژوهشگران می توانند به صورت رایگان مجوز آموزشی رایگان داشته باشند.
مطالعه موردی در Rapidminer
بیایید با Rapidminer به تمرین برویم. در این مورد مطالعه، ما یک فرآیند داده کاوی را با استفاده از مجموعه داده داخلی، با استفاده از روش طبقهبندی برای مقایسه دقت الگوریتمهای مختلف انجام خواهیم داد.
انتخاب فعالیت
این اولین رابطی است که با راه اندازی برنامه rapidminer ظاهر می شود. فرآیند خالی ساختن از ابتدا است. با کشیدن و رها کردن اپراتورها به فیلد فرآیند به صورت دستی کار می کند.اگر با این برنامه در سطح متوسط هستید، این منویی است که می خواهید انتخاب کنید.
Turbo Prep فقط برای آماده سازی مجموعه داده است. این شامل تبدیل، تمیز کردن، و ترکیب مجموعه داده ها است. Auto Model ابزار قوی را برای انجام وظایف داده کاوی به ما می آورد.
درست مثل نصب یک برنامه در ویندوز. Next-Next و Finish.همچنین قالب های زیادی برای شروع دارد. ما مدل خودکار را برای این مورد مطالعه انتخاب خواهیم کرد.
وارد کردن مجموعه داده
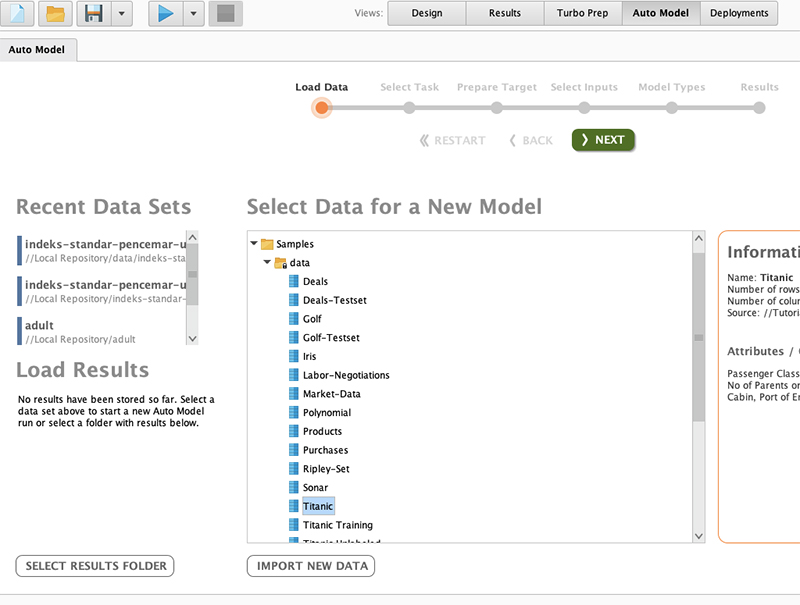
در اینجا می توانیم مجموعه داده ای را که استفاده خواهیم کرد انتخاب کنیم. ما می توانیم مجموعه داده های خود را وارد کنیم یا از مجموعه داده های موجود ارائه شده توسط rapidminer انتخاب کنیم.
دکمه Import-New-Data در زیر لیست داده های انتخاب شده برای وارد کردن مجموعه داده های خودمان است.
برای استفاده از مجموعه داده موجود از Rapidminer، روی پوشه نمونه کلیک کنید، سپس پوشه داده را گسترش دهید، و بیایید مجموعه داده Titanic را برای مورد مطالعه خود انتخاب کنیم و روی دکمه سبز رنگ Next کلیک کنیم.
توجه داشته باشید که در نوار پیشرفت تنها شش مرحله آسان برای انجام یک کار داده کاوی با rapidminer وجود دارد.
انتخاب روش داده یابی
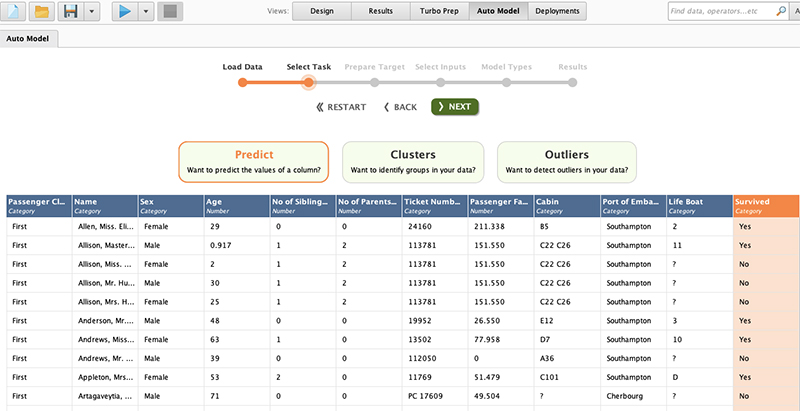
جزئیات یک مجموعه داده انتخابی نمایش داده می شود. تایتانیک مجموعه داده ای برای پیش بینی زنده ماندن مسافر در کشتی تایتانیک از روی پارامترهای ورودی موجود است.
یازده پارامتر ورودی (x) و یک برچسب (y) از این مجموعه داده وجود دارد.
سه عمل وجود دارد که می توانیم برای مجموعه داده خود انتخاب کنیم. پیش بینی، خوشه و پرت. دکمه Outliers به ما کمک می کند تا نقاط پرت را در داده های خود تشخیص دهیم.
خوشه ها به ما کمک می کنند تا گروه های مشترک را در داده هایمان شناسایی کنیم. Predict داده ها را از پارامتر ورودی داده شده طبقه بندی می کند.
در اینجا می توانیم پارامتر ورودی مجموعه داده خود را مشاهده کنیم. می بینیم که مجموعه داده تایتانیک هم از داده های دسته بندی و هم از داده های عددی تشکیل شده است. برچسب هدف به صورت قطعی، بله یا خیر است.
برای انجام طبقه بندی، دکمه پیش بینی را انتخاب کنید، ستون Survived را به عنوان برچسب یا هدف طبقه بندی انتخاب کنید و روی دکمه Next کلیک کنید.
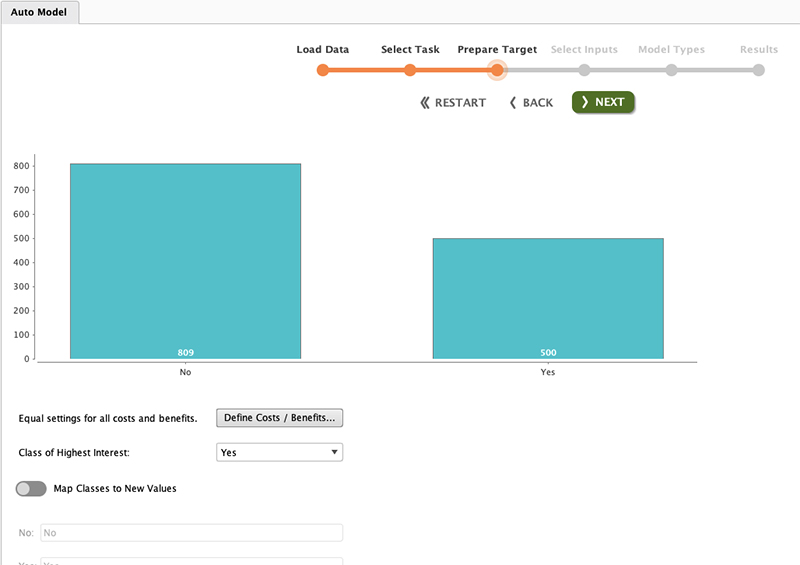
تعادل داده ها
پس از انتخاب روش داده کاوی و انتخاب ستون هدف، تراز داده در نموداری به ما ارائه می شود.ببینید که داده های خیر بیشتر از داده های بله باشد. این وضعیت در واقعیت بسیار رایج است.
این نسبت حدود 60:40 است که هنوز قابل قبول است.وقتی نسبت بالاتر از 70:30 است باید نگران باشیم. یک کلاس بسیار نامتعادل منجر به پیش بینی نامتعادل می شود.طبقه بندی معمولاً برای طبقه اکثریت پیش بینی می شود.
انتخاب ورودی
در این بخش میتوانیم ستونها را از پارامترهای ورودی حذف کنیم. به طور پیش فرض تمام ستون گنجانده شده است. Rapidminer توصیه می کند که کدام ستون ها باید گنجانده یا حذف شوند.
توجه داشته باشید که سه ردیف اول به طور پیش فرض حذف شده اند. این اتفاق می افتد زیرا وضعیت قرمز است.
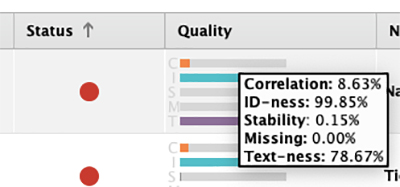
وضعیت قرمز به طور خودکار توسط rapidminer حذف می شود، اگرچه هنوز می توانیم آن را اضافه کنیم. برای مشاهده جزئیات می توانید دایره قرمز رنگ را در ستون وضعیت نگه دارید.
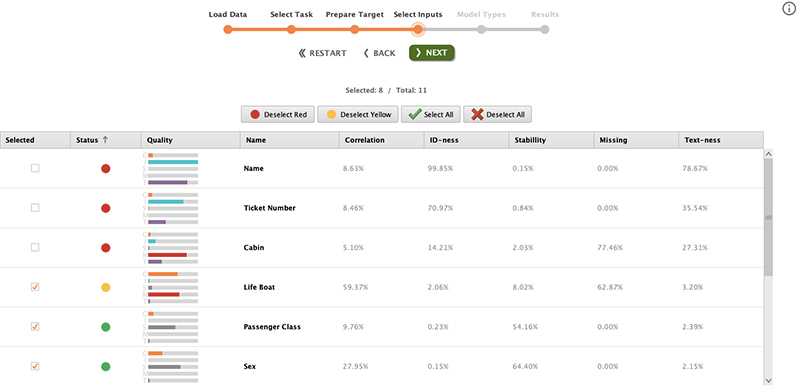
ستون کیفیت به ما در تصمیم گیری کمک می کند. از پنج پارامتر مهم CISMT تشکیل شده است.
- همبستگی (C): همبستگی خطی بین ستون داده و ستون هدف را اندازه گیری می کند.
- ID-ness (I): احتمال شباهت ستون به ID را اندازه گیری می کند.
- پایداری (S): نشان می دهد که تقریباً همه مقادیر یکسان هستند.
- Missing (M): اندازه گیری مقدار از دست رفته در ستون.
- Text-ness (T): احتمال شباهت ستون به متن آزاد را اندازه می گیرد.
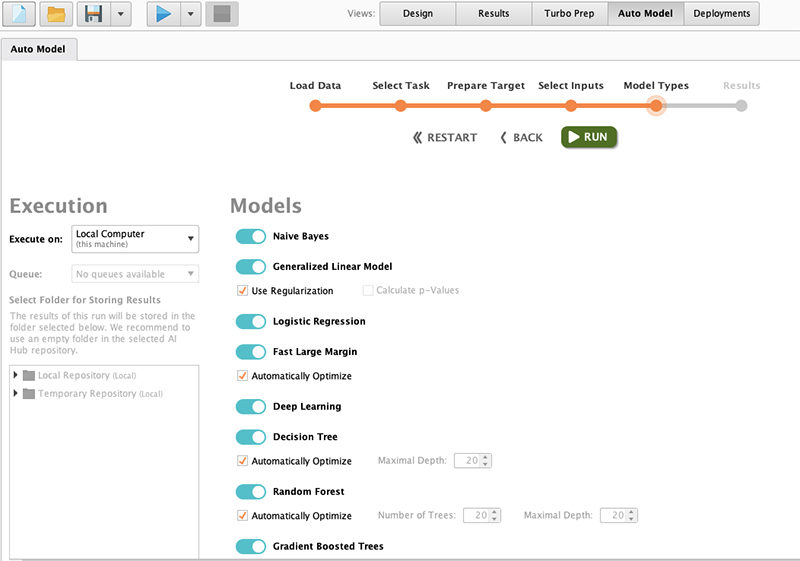
انتخاب الگوریتم
در اینجا انتخاب الگوریتم است. Rapidminer چندین الگوریتم طبقه بندی محبوب را برای ما ارائه می دهد تا بتوانیم از بین آنها انتخاب کنیم.
این لیست الگوریتم هایی است که می توانید انتخاب کنید:
- بیز ساده لوح
- مدل خطی تعمیم یافته
- رگرسیون لجستیک
- حاشیه بزرگ سریع
- یادگیری عمیق
- درخت تصمیم
- جنگل تصادفی
- درختان تقویت شده با گرادیان
- ماشین بردار پشتیبانی
اگر مجموعه داده مورد استفاده کوچک باشد، می توانیم همه آنها را انتخاب کنیم. اما هنگام استفاده از مجموعه داده بزرگ باید عاقل باشیم. زیرا هرچه الگوریتم بیشتری انتخاب شود، زمان و منابع سخت افزاری بیشتری مورد نیاز خواهد بود.
پس از انتخاب آنها بر روی دکمه run کلیک کنید.
دریافت بینش از نتیجه
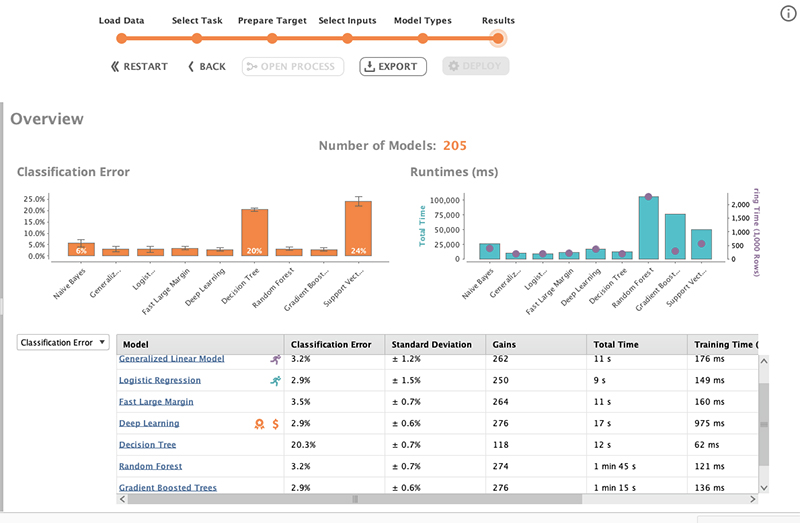
بسته به اینکه چند الگوریتم انتخاب شده است، پردازش آن زمان بیشتری خواهد برد. پس از مدتی منتظر ماندن، نتایج ارائه خواهد شد. نتایج به صورت جدول و نمودار نمایش داده می شود.
نمودار اول مقایسه خطای طبقه بندی را به ما نشان می دهد. در اینجا میتوانیم از دادههای تایتانیک خود ببینیم، DT و SVM بدترین عملکرد را نشان میدهند.
هر چه کوچکتر باشد برای نمودارها بهتر است. نمودار دوم مقایسه زمان اجرا را به ما نشان می دهد. الگوریتم درخت تصادفی بیشترین زمان اجرا را می گیرد.
در حالی که نمودارها بینشی سریع به ما می دهند، جدول جزئیات را ارائه می دهد. ستون نام مدل نیز دارای نشان است.یادگیری عمیق را ببینید، دو نشان دارد. نشانها نشان میدهند که یادگیری عمیق بهترین عملکرد کلی و بهترین محاسبات کمهزینه را دارد.
صادرات نتیجه
تصور کنید که باید داده های خود را به صورت دستی آماده کنیم و کد طبقه بندی را با یک الگوریتم یادگیری عمیق ایجاد کنیم.
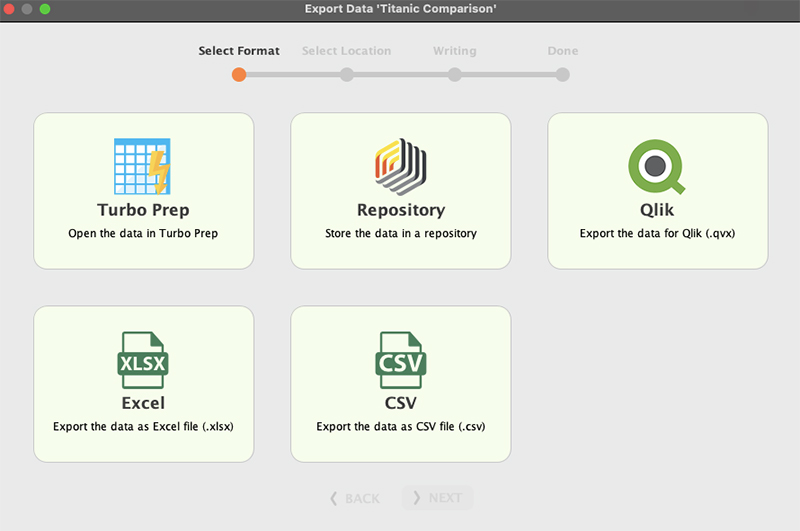
خود آن یکی باید ساعت های زیادی برای کدنویسی وقت گذاشته شود. این تنها یک الگوریتم است، چگونه می توان همه آنها را کدگذاری کرد و تجسم ها را ایجاد کرد.در عرض تنها ده دقیقه، ما در حال حاضر فرآیند داده کاوی خود را بدون سر و صدا برای کدنویسی از پایه به پایان رسانده ایم.تنها کاری که باید انجام دهیم این است که روی دکمه Next کلیک کرده و کار را تمام کنیم.ما همچنین می توانیم نتیجه را در قالب های مختلف ذخیره کنیم. اکسل یکی از آنهاست. روی دکمه صادرات از دیالوگ قبلی کلیک کنید و فقط روی فرمت مورد نظر کلیک کنید و تمام شد.
دوره آموزشی هوش تجاری با Tableau »کلیک کنید« و هوش تجاری با Power BI »کلیک کنید« یک برنامه جامع است که بر توسعه مهارت در تجزیه و تحلیل دادهها، تجسم و گزارش سازی و گزارش دهی و دشبوردسازی با استفاده از این ابزارها تمرکز دارد.
سپاسگذاریم از وقتی که برای خواندن این مقاله گذاشتید
.
برای خرید لایسنس پاور بی ای Power BI کلیک کنید
.
برای مشاهده ویدیوهای آموزشی داده کاوی و هوش تجاری ما را در شبکه های اجتماعی دنبال کنید
Youtube Chanel :VISTA Data Mining ![]()
Aparat Chanel: VISTA Data Mining ![]()
Instagram Chanel: VISTA Data Mining ![]()
Telegram Chanel: VISTA Data Mining ![]()
Linkedin Chanel: VISTA Company ![]()






