


ورود داده در نرم افزار رپیدماینر Rapidminer
در حالت ایده آل، داده های شما در حال حاضر در cluster (پوشه) قرار دارند.اگر اینطور باشد، وارد کردن به معنای جابجایی داده نیست، بلکه به معنای ایجاد شی است که اجازه دسترسی به داده ها را می دهد.اگر در cluster (پوشه) شما نیست، شامل کپی کردن داده ها از دستگاه مشتری شما است.
در هر صورت، ورود داده می تواند بخشی از فرآیند شما باشد.
این بخش از عملگرهای زیر استفاده می کند:
- Read CSV
- Read Database
- Store in Hive
- Append into Hive
- Retrieve from Hive
RapidMiner Radoop در درجه اول از Hive به عنوان یک لایه انبار داده روی Hadoop استفاده می کند.برای تعریف ساختار داده های خود به عنوان ورودی در فرآیندهای خود، از عملگرRadoop استفاده کنید.
رابط کاربری آسان به مدیریت اشیاء پایگاه داده کمک می کند در حالی که ابزارهای تجسم به شما امکان می دهند به سرعت آنها را کاوش کنید.
سناریوهای ورود اطلاعات داده در رپیدماینر
هنگامی که فرآیند ورود اطلاعات خود را طراحی می کنید، از سناریوهای اساسی زیر انتخاب کنید:
- یک جدول خارجی Hive برای داده های خود در HDFS، Amazon S3 یا Azure HDInsight تعریف کنید.
- یک جدول مدیریت شده توسط Hive برای داده های خود در HDFS تعریف کنید. داده های منبع در ساختار دایرکتوری HDFS که توسط Hive مدیریت می شود کپی می شود. شما می توانید یک قالب ذخیره سازی سفارشی برای جدول هدف تعیین کنید.
- یک جدول مدیریت شده توسط Hive برای داده های محلی در دستگاه مشتری خود تعریف کنید. دادههای ماشین محلی به HDFS در ساختار دایرکتوری مدیریت شده توسط Hive کپی میشود. توجه داشته باشید که این می تواند کندترین گزینه باشد.
در مورد اجرای ورود اطلاعات دو گزینه وجود دارد:
۱- ورود سریع اطلاعات :
Import Configuration Wizard را در Hadoop Data View باز کنید، شی منبع و هدف را مشخص کنید، سپس وارد کردن اجرا کنید.
این فقط برای جداول خارجی (که فورا ایجاد می شوند) یا HDFS کوچکتر یا منابع محلی توصیه می شود.
پیکربندی ورود اطلاعات ذخیره نمی شود و مشتری Radoop منتظر می ماند تا عملیات به پایان برسد.
نوار میزان پیشرفت عملیات را نشان می دهد.
۲- یک فرآیند ورود اطلاعات ایجاد کنید:
از نمای طراحی برای ایجاد فرآیندی که شامل یک یا چند عملیات وارد کردن داده است استفاده کنید.
از یک اپراتور از گروه اپراتور Radoop / Data Access / Read استفاده کنید.
عملگر Read CSV جادوگر پیکربندی ورود اطلاعات را باز می کند.عملگر Read Database ورود اطلاعات مشابه را برای پیکربندی ورود اطلاعات داده از یک پایگاه داده خارجی که مشتری به آن دسترسی دارد باز می کند (داده ها از طریق ماشین کلاینت جریان می یابد).عملیات ورود اطلاعات زمانی انجام می شود که فرآیند را اجرا می کنید.
اگر ممکن است بخواهید از پیکربندی مجدد استفاده کنید، واردهای دوره ای انجام دهید، برنامه ریزی کنید یا فرآیند ورود اطلاعات را با دیگران به اشتراک بگذارید، این گزینه را انتخاب کنید.
گزینه سومی برای استفاده زمانی وجود دارد که مجموعه داده یک فرآیند (ExampleSet) را از حافظه عملیاتی کلاینت در خوشه بارگیری می کنید.
این به طور خودکار توسط زنجیره اپراتور Radoop Nest انجام می شود .
هر ExampleSet متصل به هر یک از درگاه های ورودی آن به خوشه فشار داده می شود و به طور خودکار برای هر اپراتور داخل لانه که انتظار یک مجموعه داده را به عنوان ورودی دارد در دسترس قرار می گیرد.
استفاده از import wizard
ساده ترین راه برای دسترسی به ویزارد ورود اطلاعات از نمای Hadoop Data است.
پس از تکمیل مراحل، RapidMiner Radoop بلافاصله داده ها را به خوشه شما وارد می کند.
اگر بیش از یک اتصال خوشه تعریف شده دارید، اتصالی را که می خواهید برای وارد کردن استفاده کنید، درخواست می کند.
زمان ورود اطلاعات بستگی به اندازه داده های شما و اتصال به خوشه دارد.
توجه: فرآیند اساساً برای یک منبع محلی و برای یک فایل یا دایرکتوری در کلاستر یکسان است.
برای خرید لایسنس پاور بی ای Power BI کلیک کنید
راه های ورود اطلاعات در Wizard
دو راه برای باز کردن ویزارد ورود اطلاعات وجود دارد:
از نمای Hadoop Data:
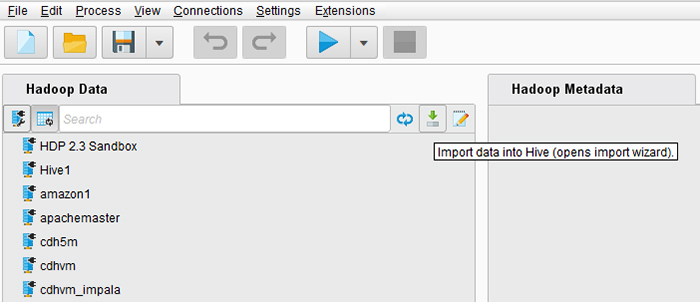
ایجاد یک فرآیند جدید با استفاده از عملگر Read CSV در داخل اپراتور Radoop Nest، سپس روی Import Configuration Wizard در پانل پارامترها کلیک کنید.
در این مورد، تکمیل مراحل تنها پارامترهای ورود اطلاعات را برای اپراتور تعریف می کند. هنگامی که فرآیند را اجرا می کنید، ورود اطلاعات انجام می شود.
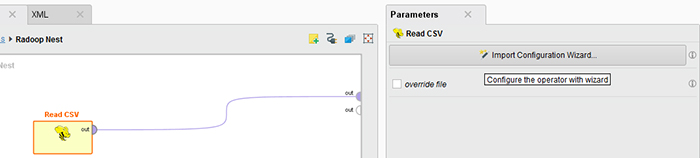
هنگامی که فرآیند خود را ذخیره می کنید، Radoop پیکربندی تعریف شده با استفاده از ویزارد در فایل پردازش را ذخیره می کند. اگر بعداً ورود اطلاعات را تکرار می کنید، ایده خوبی است که یک فرآیند ایجاد کنید.
wizard شما را از طریق مراحل زیر راهنمایی می کند تا فایل منبع را توصیف کرده و ساختار مقصد را در Hive (و در RapidMiner) تعریف کنید.
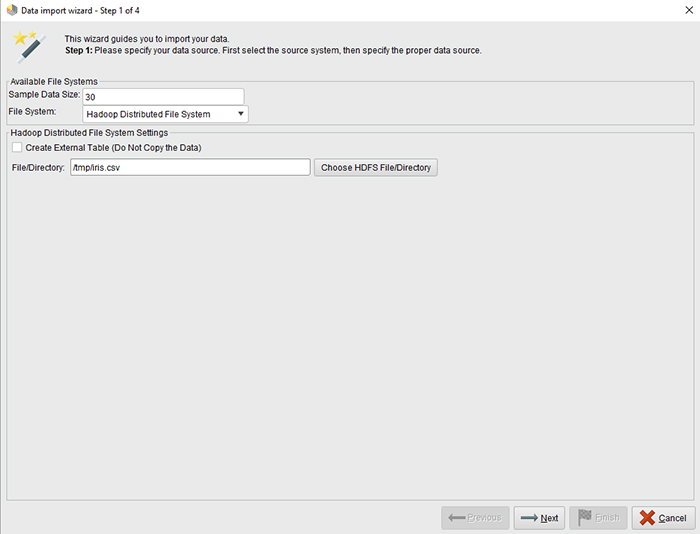
فایل محلی
پس از انتخاب، دکمه ای به شما پیشنهاد می شود که مرورگر فایل را باز می کند. روی Choose Local File کلیک کنید و فایل یا دایرکتوری ورودی را انتخاب کنید. روی نماد Next کلیک کنید تا به مرحله 2 بروید.
فایل توزیع شده Hadoop
- پس از انتخاب، دکمه ای به شما پیشنهاد می شود که مرورگر فایل را باز می کند.
- روی Choose HDFS File/Directory کلیک کنید و فایل ورودی یا دایرکتوری را انتخاب کنید.
- برای یک منبع HDFS، ممکن است بخواهید به جای آن یک جدول خارجی ایجاد کنید، که می توانید با علامت زدن کادر انتخاب ایجاد جدول خارجی… انجام دهید.
- برای یک جدول خارجی، یک فهرست منبع را انتخاب کنید.
- محتوای فایل های این دایرکتوری محتوای جدول خارجی خواهد بود.
- برای یک جدول غیر خارجی (مدیریت شده)، می توانید یک فایل یا یک فهرست کامل را به عنوان منبع انتخاب کنید.
- روی نماد Next کلیک کنید تا به مرحله 2 بروید.
سیستم ذخیره سازی ساده آمازون (S3)
- مسیر S3 و فرمت فایل را مشخص کنید.
- مسیر را طبق دستورالعمل های نشان داده شده در ویزارد وارد کنید. یکی از فرمت های فایل استاندارد فهرست شده را انتخاب کنید. یا، Custom Format را انتخاب کنید و فیلدهای ورودی و خروجی را تکمیل کنید (به عنوان مثال، نام کلاسهایی مانند org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat).
- سپس می توانید اتصال را آزمایش کنید و گزارش را برای نتایج آزمایش مشاهده کنید.
- روی نماد Next کلیک کنید تا به مرحله 2 بروید.
Rapidminer
سیستمهای ذخیرهسازی Azure HDInsight (Blob / Data Lake)
- نوع ذخیره سازی، مسیر و فرمت فایل را مشخص کنید.
- مسیری را وارد کنید که با نوع ذخیره سازی انتخاب شده مطابق با دستورالعمل های نشان داده شده در ویزارد باشد.
- یکی از فرمت های فایل استاندارد فهرست شده را انتخاب کنید.
- یا، Custom Format را انتخاب کنید و فیلدهای ورودی و خروجی را تکمیل کنید (به عنوان مثال، نام کلاسهایی مانند org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat).
- سپس می توانید اتصال را آزمایش کنید و گزارش را برای نتایج آزمایش مشاهده کنید.
- روی نماد Next کلیک کنید تا به مرحله 2 بروید.
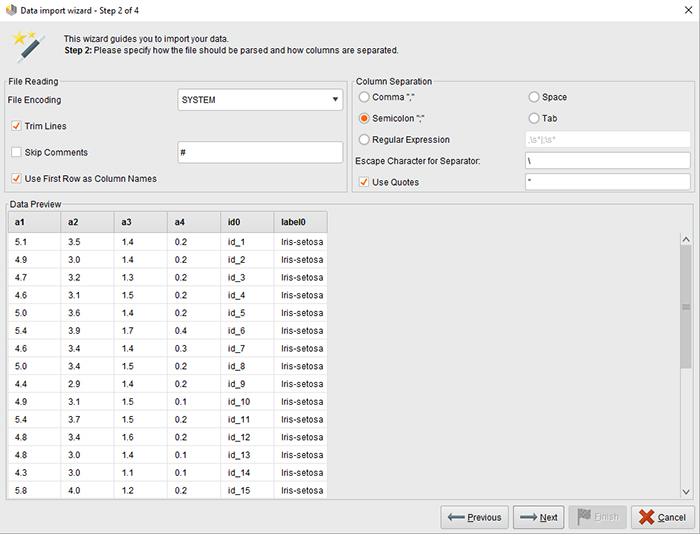
- فرمت داده های ورودی را پیکربندی کنید.
- رمزگذاری، جداکننده ستون (در صورت نیاز از یک عبارت منظم استفاده کنید)، و گزینه های دیگر، مانند خواندن نام ویژگی/ستون از خط اول را انتخاب کنید.
- سپس می توانید پیش نمایش داده های تجزیه شده را بر اساس تنظیمات موجود در صفحه پیش نمایش داده ها مشاهده کنید.
- در صورت رضایت، به مرحله بعد ادامه دهید.
Rapidminer
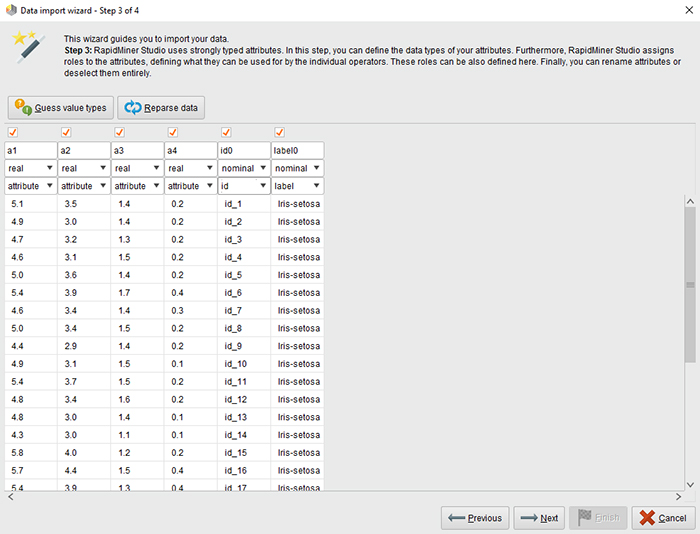
RapidMiner از ویژگی های تایپ شده قوی استفاده می کند.
این مرحله به تعریف ویژگی های جدولی که در Hive ایجاد می کنید کمک می کند. جدول مربوط به HadoopExampleSet است.
ستون های جدول ویژگی های این مجموعه مثال هستند. جادوگر انواع ویژگی ها را بر اساس مقادیری که در ابتدای فایل پیدا می کند حدس می زند.
انواع داده های مجاز عبارتند از: واقعی، عدد صحیح، اسمی و دو نامی.
RapidMiner Radoop ویژگی های واقعی و صحیح را در Hive به عنوان ستون های DOUBLE و BIGINT ذخیره می کند. ویژگی های اسمی به عنوان ستون های STRING ذخیره می شوند.ویژگی های دو نامی به عنوان ستون های STRING یا BOOLEAN ذخیره می شوند.
Radoop به صراحت از انواع دیگر پشتیبانی نمی کند، اما می توانید برای مثال، مقادیر تابع DATE را بدون هیچ مشکلی در یک ویژگی اسمی بارگذاری کنید.
بعداً می توانید آنها را با عملگرها پردازش کنید (مثلاً با Generate Attributes) و همچنین از هر یک از توابع متعدد DATE Hive روی آنها استفاده کنید.
شما همچنین می توانید نقش ها را به ویژگی ها اختصاص دهید و نحوه استفاده از آنها توسط اپراتورهای جداگانه را مشخص کنید. می توانید این نقش ها را در مراحل بعدی و همچنین با استفاده از عملگر Set Role تنظیم کنید.
رپیدماینر
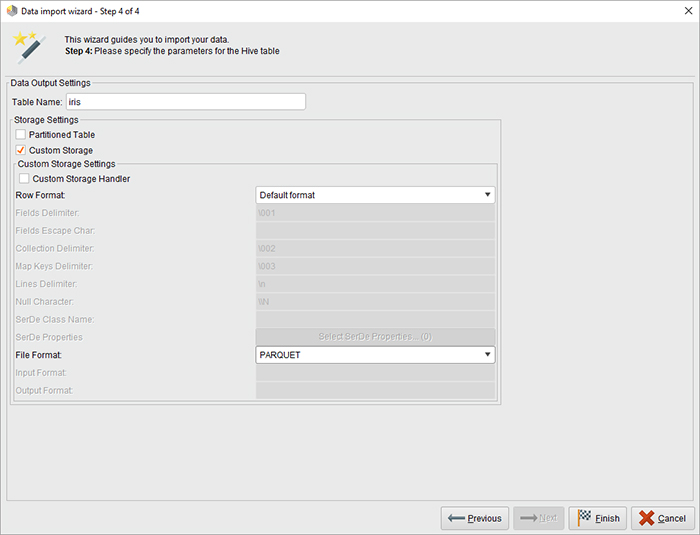
در مرحله آخر شما یک نام برای جدول Hive مقصد انتخاب می کنید و به صورت اختیاری فرمت ذخیره سازی را تغییر می دهید. اگر ویزارد را از پانل پارامترهای یک اپراتور Read CSV باز کرده اید.
همچنین می توانید انتخاب کنید که آیا می خواهید داده ها در یک جدول موقت یا دائم ذخیره شوند.
اگر میخواهید فوراً دادهها را با استفاده از سایر اپراتورهای Radoop پردازش کنید و بعداً به دادههای اصلی در این قالب نیاز ندارید، موقت را انتخاب کنید. (در هر صورت می توانید داده های پردازش شده را با اپراتور Store in Hive ذخیره کنید.)
میتوانید بهصورت اختیاری، قالب ذخیرهسازی پیشفرض یک جدول دائمی را که توسط تنظیمات Fileformat Hive (یا به عنوان پارامتر) تعریف شده است، با انتخاب گزینه Custom storage تغییر دهید.
می توانید از پارتیشن بندی استفاده کنید که ممکن است عملکرد پرس و جو را هنگام فیلتر کردن ستون پارتیشن بندی افزایش دهد. فرمتهای ذخیرهسازی ویژه ممکن است فضای مورد نیاز را کاهش داده و کارایی را افزایش دهند، اما توجه داشته باشید که انتخاب یک قالب خاص میتواند زمان اجرای واردات را افزایش دهد زیرا تبدیل ممکن است به سربار اضافی نیاز داشته باشد. برای جزئیات انواع ذخیره سازی به اسناد کندو مراجعه کنید.
Rapidminer
پس از وارد کردن دادهها به خوشه، میتوانید به راحتی با استفاده از نمای Hadoop Data به آن دسترسی داشته باشید، پرس و جو کنید و آنها را تجسم کنید.
با استفاده از عملگر Retrieve from Hive می توانید به داده های وارد شده در یک فرآیند دسترسی داشته باشید.
روی شی در این نما کلیک راست کرده و روی Create Process: Retrieve کلیک کنید تا فوراً یک فرآیند Radoop جدید ایجاد کنید که از این داده ها به عنوان ورودی استفاده می کند.
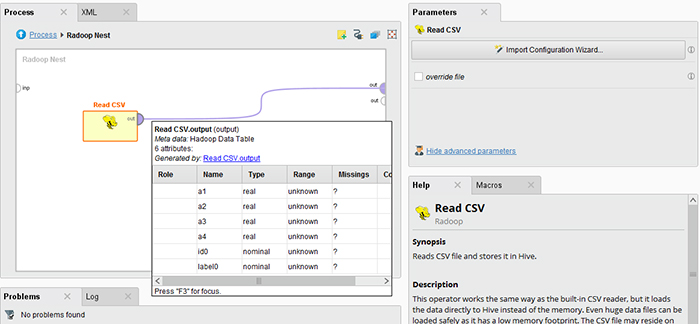
اگر ویزارد را برای تعریف پارامترهای یک اپراتور Read CSV از نمای Design باز کرده باشید.
میتوانید بلافاصله ابردادههایی را که در درگاه خروجی اپراتور ظاهر میشوند، کاوش کنید (همانطور که با عملگر Retrieve from Hive پس از انتخاب جدول ورودی که ایجاد کردهاید).
خواندن پایگاه داده
Radoop همچنین می تواند داده ها را از یک پایگاه داده دریافت کند.کلاینت از اتصال پایگاه داده تعریف شده می خواند و داده ها را فوراً به خوشه می فرستد.منبع می تواند یک شی پایگاه داده باشد، بلکه نتیجه یک پرس و جو است که در یک پارامتر تعریف می کنید.
اپراتور از اتصالات به MySQL، PostgreSQL، Sybase، Oracle، HISQLDB، Ingres، Microsoft SQL Server یا هر پایگاه داده دیگری که از پل ODBC استفاده می کند، پشتیبانی می کند.
توجه: نرم افزار ممکن است حاوی درایور JDBC منبع بسته برای سیستم های پایگاه داده خاص نباشد.
در این صورت فایل درایور را دانلود کنید.از لینک زیر استفاده نمایید-لینک بشه به مقاله قبلی اتصال به پایگاه داده در rapidminer
بارگیری از حافظه
برای بارگیری داده ها از حافظه عملیاتی مشتری، یک اپراتور هسته RapidMiner را که یک شی ExampleSet را در خروجی خود ارائه می دهد، به ورودی اپراتور Radoop Nest متصل کنید.
دسترسی به داده ها در Hive
با اپراتور Store in Hive، می توانید مجموعه داده های فعلی را در فرآیند خود ذخیره کنید.
از آنجایی که دادههای داخل Radoop Nest همیشه در خوشه قرار میگیرند، ذخیرهسازی به طور مؤثر به معنای ذخیره ساختار و خود دادهها در جدول Hive برای استفاده بعدی است (یعنی پس از تکمیل فرآیند حذف نمیشوند).
فرآیند ذخیره سازی زمان بر نیست، اگرچه محاسبات به تعویق افتاده ممکن است قبل از تکمیل آن به پایان برسد.
برای دسترسی به جداول Hive از عملگر Retrieve from Hive استفاده کنید.
داده ها را از جدول انتخاب شده در پورت خروجی خود تحویل می دهد.
تا زمانی که یک درگاه خروجی اپراتور Radoop را به خروجی Radoop Nest متصل نکنید، داده ها روی خوشه باقی می مانند. در این حالت، نمونه ای از داده ها به حافظه عملیاتی ماشین کلاینت واکشی می شود.
اگر جدول هدف هنوز وجود نداشته باشد، Append into Hive مشابه عملگر Store in Hive است.
اگر وجود داشته باشد، اپراتور ابتدا بررسی می کند که آیا ساختار جدول با ساختار مجموعه داده در پورت ورودی آن یکسان است یا خیر.
همچنین اگر مطابقت داشته باشند، داده ها به جدول مقصد فعلی اضافه می شوند.
اگر ساختارها متفاوت باشند، سیستم خطاهای زمان طراحی و زمان اجرا را ایجاد می کند.
دوره آموزشی هوش تجاری با Tableau »کلیک کنید« و هوش تجاری با Power BI »کلیک کنید« یک برنامه جامع است که بر توسعه مهارت در تجزیه و تحلیل دادهها، تجسم و گزارش سازی و گزارش دهی و دشبوردسازی با استفاده از این ابزارها تمرکز دارد.
سپاسگذاریم از وقتی که برای خواندن این مقاله گذاشتید
.
برای خرید لایسنس تبلو Tableau کلیک کنید
.
برای مشاهده ویدیوهای آموزشی داده کاوی و هوش تجاری ما را در شبکه های اجتماعی دنبال کنید
Youtube Chanel :VISTA Data Mining ![]()
Aparat Chanel: VISTA Data Mining ![]()
Instagram Chanel: VISTA Data Mining ![]()
Telegram Chanel: VISTA Data Mining ![]()
Linkedin Chanel: VISTA Company ![]()
