


پیش نیاز انجام هرگونه عملیات مرتبط با داده در Python ، مانند پاکسازی داده ها ، تجمیع داده ها ، تبدیل داده ها و تجسم داده ها ، بارگذاری داده ها در Python است.
به انواع پرونده های داده (به عنوان مثال .csv ، .txt ، .tsv ، .html ، .json ، صفحات گسترده اکسل ، پایگاه داده های رابطه ای و غیره) و اندازه آنها بستگی دارد .
روش های مختلفی برای انجام با این عملیات اولیه وجود دارد که در این پست ، چند روش معمول برای وارد کردن داده ها در Python را لیست می کنیم.
طبق معمول ، از Github من می توان به تمام داده ها و نوت بوک های مورد نیاز دسترسی داشت.
۱- توابع داخلی پایتون (read(), readline(), and readlines())
به طور کلی ، یک فایل متنی (.txt) متداولترین پرونده ای است که با آن روبرو خواهیم شد. پرونده های متنی به صورت دنباله ای از سطرها ساخته می شوند ، جایی که هر خط شامل دنباله ای از کاراکترها است.
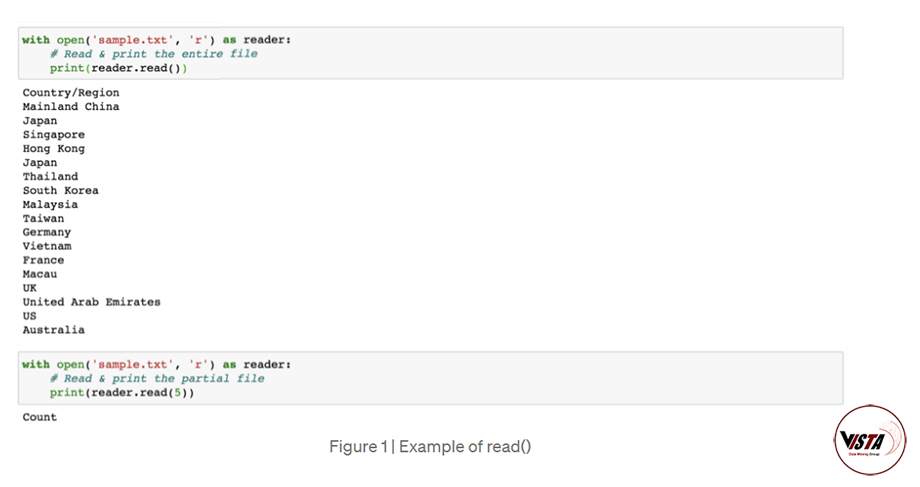
بیایید فرض کنیم که ما باید فایل متنی زیر را در Python وارد کنیم (sample.txt).

برای وارد کردن محتوای آن به پایتون ، ابتدا باید آن را باز کنیم.
این مرحله درست مانند دوبار کلیک کردن روی پرونده است تا در سیستم رایانه ای ما باز شود. اما ، در Python این کار با فراخوانی تابع open () داخلی انجام می شود.
open () یک آرگومان مورد نیاز دارد که مسیر پرونده است و یک آرگومان اختیاری برای نشان دادن حالت (به عنوان مثال آرگومان پیش فرض “r”: باز برای خواندن ؛ “w”: باز برای نوشتن).
با تنظیمات ، () را باز کنید و سپس یک شی file پرونده به ما بازگردانید.
برای خواندن محتوا سه روش وجود دارد (به عنوان مثال read () ، readline () و readlines ()) که می توان روی این شی object پرونده را به صورت یک یا به صورت ترکیبی فراخوانی کرد.
read (size = -1): این بر اساس تعداد بایت اندازه از پرونده می خواند.
اگر هیچ آرگومان منتقل نشود یا None یا -1 تصویب نشود ، کل پرونده خوانده می شود.
زبان برنامه نویسی پایتون
readline (size = -1): این کل خط را می خواند اگر هیچ آرگومان منتقل نشود یا None یا -1 عبور نکند (شکل 2 پانل بالایی).
یا اگر با اندازه عبور داده شود ، این تعداد کاراکترهای خط را می خواند.
علاوه بر این ، چندین توابع readline () (شکل 2 پانل پایین) را می توان به ترتیب نامید ، که در آن تابع readline () بعدی از موقعیت انتهایی آخرین تابع readline () ادامه می یابد.
توجه داشته باشید که خروجی خط خوان سوم () یک کاراکتر خط جدید اضافه می کند (\ n ، به عنوان یک خط جدید نمایش داده می شود).
با استفاده از چاپ (reader.readline(5), end=’’). می توان از این امر جلوگیری کرد.

readlines (): این خطوط یا خطوط باقی مانده از شی پرونده را می خواند و آنها را به صورت لیست برمی گرداند (شکل 3).

ممکن است متوجه شوید که همه کدهای بالا دارای عبارت هستند.
گزاره با روشی فراهم می کند تا اطمینان حاصل شود که پرونده پس از باز شدن همیشه بسته است.
بدون عبارت ما به صراحت باید close () را برای شی file پرونده فراخوانی کنیم. برای مثال:

از آنجا که فراموش کردن بستن پرونده بسیار آسان است ، ما باید همیشه از دستور استفاده کنیم.
Python csv library

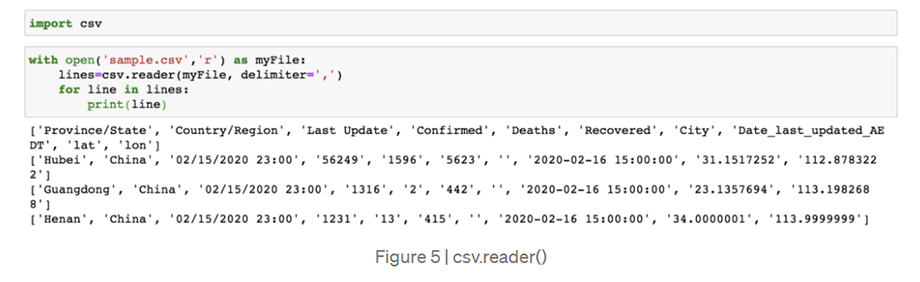
نمونه.txt که ما قبلاً پردازش کردیم فقط یک فیلد در هر خط داشت که پردازش آن را فقط با استفاده از تابع داخلی (read () ، readline () و readlines ()) مفید می کند. با این حال ، بیشتر اوقات ، مانند آنچه در شکل 4 نشان داده شده است ، با فایلی کار خواهیم کرد که دارای چندین زمینه در هر سطر است (یا داده های جدولی).

همانطور که می بینیم هر فیلد در هر خط با کاما از هم جدا شده است ، نشان می دهد که یک قسمت به کجا پایان می یابد و قسمت بعدی شروع می شود.
ما به این نوع پرونده ها فایل محدود شده می گوییم.
این پرونده ها اغلب یا با کاما (.csv) یا با زبانه جدا شده اند (.tsv یا .txt). در موارد نادر ، ممکن است با جداکننده های دیگری مانند کولون (:) ، نیمه کولون (؛)نیز روبرو شوید.
حتی اگر عملکرد داخلی همچنان بتواند این پرونده ها را پردازش کند ، به احتمال زیاد بهم ریخته می شود ، مخصوصاً وقتی در هر مورد صدها فایل در هر خط وجود دارد.
متناوباً ، می توانیم از کتابخانه csv Python استفاده کنیم که برای خواندن پرونده های محدود شده طراحی شده است.
در اینجا بیایید دو عملکرد مشترک را از این ماژول بیاموزیم.
- csv.reader (): این همه خطوط موجود در فایل داده شده را خوانده و یک شی خواننده را برمی گرداند.
سپس هر خط می تواند به عنوان لیستی از رشته ها برگردانده شود.
- csv.DictReader: سپس می توانیم با فراخوانی نام فیلد آن ، به داده های هر ستون دسترسی پیدا کنیم
دوره آموزشی زبان برنامه نویسی پایتون »کلیک کنید» یک برنامه جامع است که بر توسعه سریع نرمافزارهای کاربردی، برنامهنویسی شیگرا و کاربری ماژول و…. با استفاده از ابزار Python تمرکز دارد.
سپاسگذاریم از وقتی که برای خواندن این مقاله گذاشتید
.
برای خرید لایسنس پاور بی ای Power BI کلیک کنید
.
برای مشاهده ویدیوهای آموزشی داده کاوی و هوش تجاری ما را در شبکه های اجتماعی دنبال کنید
Youtube Chanel :VISTA Data Mining ![]()
Aparat Chanel: VISTA Data Mining ![]()
Instagram Chanel: VISTA Data Mining ![]()
Telegram Chanel: VISTA Data Mining ![]()
Linkedin Chanel: VISTA Company ![]()
