

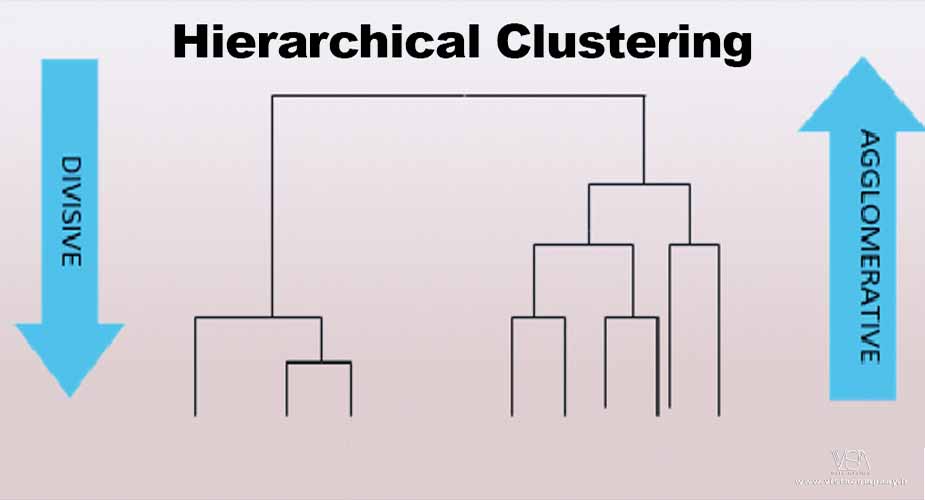
Hierarchical Clustering در Machine Learning
در دنیای واقعی داده ها اغلب فاقد متغیر هدف هستند که یادگیری تحت نظارت را غیرعملی می کند. آیا تا به حال فکر کرده اید که چگونه شبکه های اجتماعی مانند فیس بوک به دوستان خود توصیه می کنند یا چگونه دانشمندان گونه های مشابه را با هم گروه بندی می کنند؟ اینها نمونه هایی از خوشه بندی سلسله مراتبی است که در این مقاله با آنها آشنا خواهیم شد.
چرا خوشه بندی سلسله مراتبی؟
خوشه بندی سلسله مراتبی تکنیکی است که برای گروه بندی نقاط داده مشابه با هم بر اساس شباهت آنها ایجاد یک ساختار سلسله مراتبی یا درخت مانند استفاده می شود. ایده اصلی این است که با هر نقطه داده به عنوان خوشه جداگانه شروع شود و سپس به تدریج آنها را بر اساس شباهتشان ادغام یا تقسیم کنیم.
بیایید این را با کمک یک مثال درک کنیم
تصور کنید چهار میوه با وزن های مختلف دارید: یک سیب (100 گرم)، یک موز (120 گرم)، یک گیلاس (50 گرم)، و یک انگور (30 گرم). خوشه بندی سلسله مراتبی با در نظر گرفتن هر میوه به عنوان گروه خاص خود شروع می شود.
- سپس نزدیکترین گروه ها را بر اساس وزن آنها ادغام می کند.
- ابتدا گیلاس و انگور را با هم دسته بندی می کنند زیرا سبک ترین هستند.
- در مرحله بعد، سیب و موز با هم گروه بندی می شوند.
در نهایت، همه میوهها در یک گروه بزرگ ادغام میشوند و نشان میدهند که چگونه خوشهبندی سلسله مراتبی به تدریج مشابهترین نقاط داده را ترکیب میکند.
شروع کار با Dendogram
دندروگرام مانند یک درخت خانوادگی برای خوشه ها است. این نشان می دهد که چگونه نقاط داده یا گروه های داده جداگانه با هم ادغام می شوند. قسمت پایین هر نقطه داده را به عنوان گروه خاص خود نشان می دهد، و با حرکت به سمت بالا، گروه های مشابه ترکیب می شوند. هر چه نقطه ادغام کمتر باشد، گروه ها بیشتر شبیه هم هستند. این به شما کمک می کند تا ببینید چگونه چیزها گام به گام گروه بندی می شوند.
کار دندروگرام را می توان با استفاده از نمودار زیر توضیح داد:
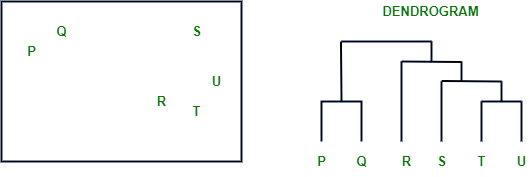
در این تصویر، در سمت چپ، پنج نقطه با برچسب P، Q، R، S و T وجود دارد. این نقاط دادهای را نشان میدهند که در حال خوشهبندی هستند. در سمت راست، یک دندروگرام وجود دارد که نشان می دهد چگونه این نقاط در کنار هم گام به گام گروه بندی می شوند.
- در پایین دندروگرام، نقاط P، Q، R، S و T همگی از هم جدا هستند.
- همانطور که به سمت بالا حرکت می کنید، نزدیک ترین نقاط در یک گروه ادغام می شوند.
- خطوطی که نقاط را به هم متصل می کنند نشان می دهد که چگونه آنها بر اساس شباهت به تدریج ادغام می شوند.
- ارتفاعی که آنها در آن به هم متصل می شوند نشان می دهد که چقدر نقاط به یکدیگر شبیه هستند. هر چه خط کوتاه تر باشد، شباهت بیشتری دارند
انواع خوشه بندی سلسله مراتبی
اکنون که اصول خوشه بندی سلسله مراتبی را درک کردیم، بیایید دو نوع اصلی خوشه بندی سلسله مراتبی را بررسی کنیم.
- Agglomerative Clustering (تجمیعی)
- Divisive Clustering (تقسیمی)
خوشه بندی سلسله مراتبی Agglomerative Clustering
همچنین به عنوان رویکرد از پایین به بالا یا خوشه بندی تجمعی سلسله مراتبی (HAC) شناخته می شود. بر خلاف خوشه بندی مسطح، خوشه بندی سلسله مراتبی روشی ساختاریافته برای گروه بندی داده ها ارائه می دهد. این الگوریتم خوشهبندی نیازی به تعیین تعداد خوشهها ندارد. الگوریتمهای پایین به بالا در ابتدا هر داده را بهعنوان یک خوشه تکتنه در نظر میگیرند و سپس بهطور متوالی جفتهایی از خوشهها را جمعآوری میکنند تا زمانی که همه خوشهها در یک خوشه واحد که شامل همه دادهها است ادغام شوند.
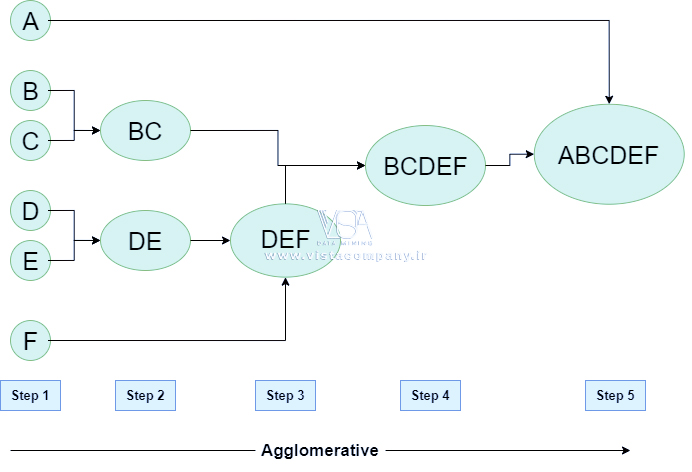
Workflow (گردش کار) برای خوشه بندی سلسله مراتبی تجمیعی
- با نقاط منفرد شروع کنید: هر نقطه داده خوشه خودش است. به عنوان مثال، اگر 5 نقطه داده دارید، با 5 خوشه شروع می کنید که هر کدام فقط یک نقطه داده را شامل می شود.
- محاسبه فاصله بین خوشه ها: فاصله بین هر جفت خوشه را محاسبه کنید. در ابتدا از آنجایی که هر خوشه یک نقطه دارد، این فاصله بین دو نقطه داده است.
- ادغام نزدیکترین خوشه ها: دو خوشه را با کمترین فاصله مشخص کنید و آنها را در یک خوشه ادغام کنید.
- به روز رسانی ماتریس فاصله: پس از ادغام، اکنون یک خوشه کمتر دارید. فاصله بین خوشه جدید و خوشه های باقی مانده را دوباره محاسبه کنید.
- مراحل 3 و 4 را تکرار کنید: به ادغام نزدیکترین خوشه ها و به روز رسانی ماتریس فاصله ادامه دهید تا زمانی که فقط یک خوشه باقی بماند.
- یک دندروگرام ایجاد کنید: با ادامه روند می توانید ادغام خوشه ها را با استفاده از یک نمودار درخت مانند به نام دندروگرام تجسم کنید. این سلسله مراتب نحوه ادغام خوشه ها را نشان می دهد.
برای خرید لایسنس پاور بی ای Power BI کلیک کنید
پیاده سازی پایتون الگوریتم فوق با استفاده از کتابخانه scikit-learn:
from sklearn.cluster import AgglomerativeClustering import numpy as np X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]]) clustering = AgglomerativeClustering(n_clusters=2).fit(X) print(clustering.labels_)
خروجی :
[1, 1, 1, 0, 0, 0]
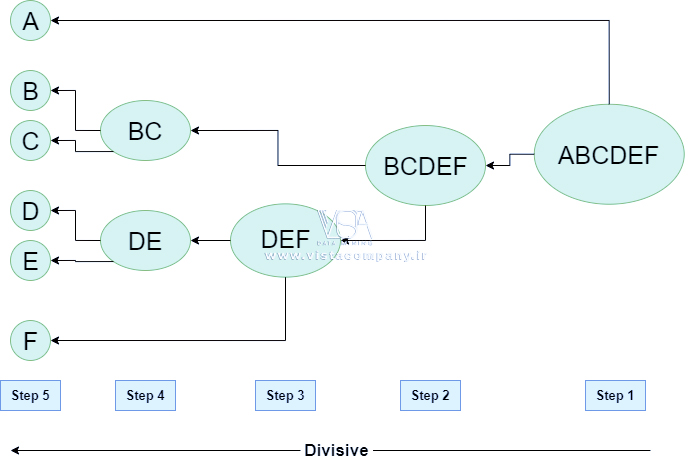
خوشه بندی سلسله مراتبی Divisive Clustering
همچنین به عنوان رویکرد از بالا به پایین شناخته می شود. این الگوریتم همچنین نیازی به تعیین تعداد خوشهها ندارد. خوشهبندی از بالا به پایین به روشی برای تقسیم یک خوشه نیاز دارد که شامل کل دادهها باشد و با تقسیم خوشهها به صورت بازگشتی تا زمانی که دادههای فردی به خوشههای تک تنی تقسیم شوند، ادامه مییابد.
Workflow (گردش کار) برای خوشه بندی سلسله مراتبی تقسیمی:
- با تمام نقاط داده در یک خوشه شروع کنید: کل مجموعه داده را به عنوان یک خوشه بزرگ در نظر بگیرید.
- تقسیم خوشه: خوشه را به دو خوشه کوچکتر تقسیم کنید. این تقسیم معمولاً با یافتن دو نقطه متفاوت در خوشه و استفاده از آنها برای جدا کردن داده ها به دو قسمت انجام می شود.
- تکرار فرآیند: برای هر یک از خوشه های جدید، فرآیند تقسیم را تکرار کنید:
- خوشه ای را انتخاب کنید که بیشترین نقاط مشابه را دارد.
- دوباره آن را به دو دسته کوچکتر تقسیم کنید.
- توقف زمانی که هر نقطه داده در خوشه خودش باشد: این فرآیند را تا زمانی ادامه دهید که هر نقطه داده خوشه خودش باشد یا شرط توقف (مانند تعداد از پیش تعریف شده خوشه) برآورده شود.
ماتریس فاصله محاسباتی
هنگام ادغام دو خوشه، فاصله بین دو هر جفت خوشه را بررسی می کنیم و جفت را با کمترین فاصله/ بیشترین شباهت ادغام می کنیم. اما سوال اینجاست که این فاصله چگونه تعیین می شود. راه های مختلفی برای تعریف فاصله/شباهت بین خوشه ای وجود دارد. برخی از آنها عبارتند از:
- حداقل فاصله: حداقل فاصله بین هر دو نقطه از خوشه را بیابید.
- حداکثر فاصله: حداکثر فاصله بین هر دو نقطه از خوشه را بیابید.
- میانگین گروه: میانگین فاصله بین هر دو نقطه از خوشه ها را بیابید.
- روش وارد: تشابه دو خوشه بر اساس افزایش مجذور خطا در هنگام ادغام دو خوشه است.

کد پیاده سازی برای مقایسه ماتریس فاصله
import numpy as np from scipy.cluster.hierarchy import dendrogram, linkage import matplotlib.pyplot as plt X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]]) Z = linkage(X, ‘ward’) # Ward Distance dendrogram(Z) #plotting the dendogram plt.title(‘Hierarchical Clustering Dendrogram’) plt.xlabel(‘Data point’) plt.ylabel(‘Distance’) plt.show()
خروجی :
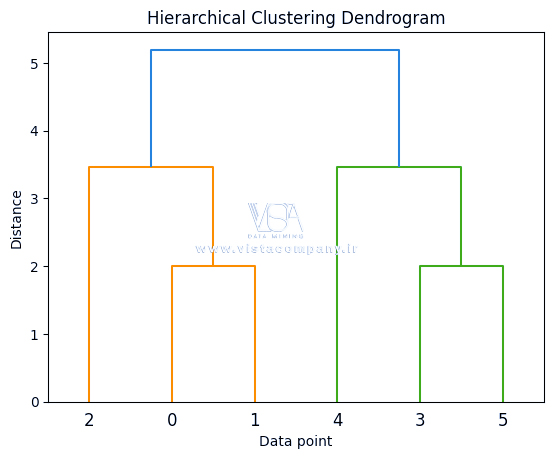
خوشهبندی سلسله مراتبی یک تکنیک یادگیری بدون نظارت قدرتمند است که دادهها را در ساختاری درختمانند سازماندهی میکند و به ما اجازه میدهد تا روابط بین نقاط داده را با استفاده از دندروگرام تجسم کنیم. برخلاف روشهای خوشهبندی مسطح، به تعداد خوشههای از پیش تعریفشده نیاز ندارد و روشی ساختاریافته برای کشف شباهت دادهها ارائه میکند.
سوالات متداول (پرسش های متداول) در مورد خوشه بندی سلسله مراتبی
خوشه بندی سلسله مراتبی چیست؟
خوشه بندی سلسله مراتبی تکنیکی است که برای گروه بندی نقاط داده مشابه بر اساس شباهت آنها، ایجاد یک ساختار سلسله مراتبی یا درخت مانند استفاده می شود. این شامل ادغام یا تقسیم تدریجی نقاط داده بر اساس شباهت آنها است.
دو نوع خوشه بندی سلسله مراتبی چیست؟
دو نوع اصلی خوشه بندی سلسله مراتبی وجود دارد:
- خوشهبندی تجمیعی | Agglomerative Clustering : رویکردی از پایین به بالا که در آن هر نقطه داده بهعنوان خوشه خاص خود شروع میشود و به تدریج با نزدیکترین خوشه ادغام میشود.
- خوشه بندی تقسیمی | Divisive Clustering: رویکردی از بالا به پایین که در آن تمام نقاط داده به عنوان یک خوشه منفرد شروع می شوند که به صورت بازگشتی به خوشه های کوچکتر تقسیم می شوند.
خوشه بندی سلسله مراتبی تجمیعی چگونه کار می کند؟
در خوشه بندی تجمیعی، هر نقطه داده به عنوان خوشه خاص خود شروع می شود. این الگوریتم فاصله بین خوشه ها را محاسبه می کند، نزدیک ترین خوشه ها را ادغام می کند و این فرآیند را تا زمانی که تمام نقاط داده در یک خوشه ادغام شوند، تکرار می کند. نتیجه در دندروگرام مشاهده می شود
دندروگرام در خوشه بندی سلسله مراتبی چیست؟
دندروگرام یک نمودار درخت مانند است که به صورت بصری ساختار سلسله مراتبی خوشه ها را نشان می دهد. نشان میدهد که چگونه نقاط داده یا خوشهها در هر مرحله از فرآیند خوشهبندی ادغام یا تقسیم میشوند، با ارتفاع شاخهها نشاندهنده فاصلهای که در آن ادغام یا تقسیم رخ میدهد.
چگونه روش مناسب را برای خوشه بندی سلسله مراتبی انتخاب کنم؟
انتخاب روش بستگی به ساختار داده های شما دارد. به عنوان مثال:
- حداقل فاصله برای خوشه های دراز به خوبی کار می کند.
- Max Distance خوشه های فشرده و کاملاً جدا شده ایجاد می کند.
- میانگین گروه یک رویکرد متعادل ارائه می دهد.
- روش Ward تلاش می کند تا افزایش خطای مربع را به حداقل برساند و خوشه های فشرده را حفظ کند.
امیدواریم از این پست لذت برده باشید
برای مطالب بیشتر از وب سایت ما از جمله مطالعات موردی اضافی، اخبار و رویدادها، و نکات و ترفندهایی برای ارتقای تجزیه و تحلیل بصری خود، از وب سایت ما دیدن کنید.
رسانه های اجتماعی ما را برای به روز رسانی نرم افزارهای، BI و AI دنبال کنید.
امیدواریم این اطلاعات بیشتر به شما کمک کند تا انتخابی مناسب برای کسب و کار و سازمانتان داشته باشید. اگر هنوز مطمئن نیستید، نگران نباشید،تیم پشتیبانی داده کاوی ویستا اینجاست تا به شما کمک کند!
همین امروز با ما تماس بگیرید، و ما می توانیم با هم همکاری کنیم تا در فرآیند تصمیم گیری به شما کمک کنیم و ترکیب بهینه محصولات را برای شما پیدا کنیم.
دوره آموزشی زبان برنامه نویسی پایتون »کلیک کنید» یک برنامه جامع است که بر توسعه سریع نرمافزارهای کاربردی، برنامهنویسی شیگرا و کاربری ماژول و…. با استفاده از ابزار Python تمرکز دارد.
سپاسگذاریم از وقتی که برای خواندن این مقاله گذاشتید
برای خرید لایسنس Tableau کلیک کنید
برای مشاهده ویدیوهای آموزشی داده کاوی و هوش تجاری ما را در شبکه های اجتماعی دنبال کنید
Youtube Chanel :VISTA Data Mining ![]()
Aparat Chanel: VISTA Data Mining ![]()
Instagram Chanel: VISTA Data Mining ![]()
Telegram Chanel: VISTA Data Mining ![]()
Linkedin Chanel: VISTA Company ![]()
