


درخت تصمیم (Decision Tree)
درخت تصمیم (Decision Tree)، درختی مانند مجموعه ای از گره ها است که برای ایجاد یک تصمیم در مورد وابستگی مقادیر به یک کلاس یا تخمینی از یک مقدار هدف عددی در نظر گرفته شده است.
هر گره یک قانون تقسیم را برای یک ویژگی خاص نشان می دهد. برای طبقه بندی، این قانون مقادیر متعلق به کلاس های مختلف را جدا می کند، برای رگرسیون آنها را جدا می کند تا خطا را به روشی بهینه برای معیار پارامتر انتخاب شده کاهش دهد.
ساخت گره های جدید تا زمانی که معیارهای توقف برآورده شود تکرار می شود. یک پیشبینی برای برچسب کلاس Attribute بسته به اکثر مثالهایی که در طول تولید به این برگ رسیدهاند تعیین میشود، در حالی که یک تخمین برای یک مقدار عددی با میانگینگیری مقادیر در یک برگ به دست میآید.
این اپراتور می تواند ExampleSets را پردازش کند که شامل ویژگی های اسمی و عددی است.
برچسب Attribute باید برای طبقه بندی اسمی و برای رگرسیون عددی باشد.
پس از تولید، مدل درخت تصمیم را می توان با استفاده از Apply Model Operator برای مثال های جدید اعمال کرد. هر مثال شاخه های درخت را مطابق با قانون شکافتن دنبال می کند تا زمانی که به یک برگ برسد.
برای خرید لایسنس تبلو Tableau کلیک کنید
تفکیک
CHAID
اپراتور CHAID یک درخت تصمیم هرس شده را ارائه می دهد که از معیار مبتنی بر مجذور کای به جای معیارهای نسبت به دست آوردن یا افزایش اطلاعات استفاده می کند.
این عملگر را نمی توان روی ExampleSets با ویژگی های عددی و فقط با ویژگی های اسمی اعمال کرد.
ID3
اپراتور ID3 یک پیاده سازی اساسی از درخت تصمیم هرس نشده را فراهم می کند. فقط با ExampleSets با ویژگی های اسمی کار می کند.
Random Forest
عملگر جنگل تصادفی چندین درخت تصادفی را در زیر مجموعه های مختلف مثال ایجاد می کند.
مدل به دست آمده بر اساس رای دادن به همه این درختان است. با توجه به این تفاوت، کمتر در معرض تمرین بیش از حد است.
Bagging
Bootstrap Aggregating (bagging) یک متاالگوریتم مجموعه یادگیری ماشینی برای بهبود مدلهای طبقهبندی و رگرسیون از نظر پایداری و دقت طبقهبندی است.
همچنین واریانس را کاهش میدهد و به جلوگیری از «برازش بیش از حد» کمک میکند. اگرچه معمولاً برای مدلهای درخت تصمیم استفاده میشود، اما میتوان آن را با هر نوع مدلی استفاده کرد.
ورودی
مجموعه آموزشی (جدول داده ها)
داده های ورودی که برای تولید مدل درخت تصمیم استفاده می شود.
خروجی
مدل (درخت تصمیم)
مدل درخت تصمیم از این پورت خروجی تحویل داده می شود.
مجموعه نمونه (جدول داده)
ExampleSet که به عنوان ورودی داده شد بدون تغییر به خروجی از طریق این پورت ارسال می شود.
وزن ها (وزن های ویژگی)
یک ExampleSet حاوی ویژگی ها و مقادیر وزن، که در آن هر وزن نشان دهنده اهمیت ویژگی برای ویژگی داده شده است. وزن با مجموع بهبودهایی که انتخاب یک ویژگی داده شده در یک گره ارائه می شود، داده می شود.
میزان بهبود بستگی به معیار انتخاب شده دارد.
مولفه های معیار
معیاری را انتخاب می کند که بر اساس آن ویژگی ها برای تقسیم انتخاب می شوند. برای هر یک از این معیارها مقدار تقسیم با توجه به معیار انتخاب شده بهینه شده است. می تواند یکی از مقادیر زیر را داشته باشد:
information_gain: آنتروپی تمام ویژگی ها محاسبه می شود و آنتروپی با کمترین آنتروپی برای تقسیم انتخاب می شود. این روش نسبت به انتخاب ویژگی هایی با تعداد زیادی مقادیر تعصب دارد.
gain_ratio: گونهای از بهره اطلاعاتی که به دست آوردن اطلاعات را برای هر ویژگی تنظیم میکند تا وسعت و یکنواختی مقادیر Attribute را مجاز کند.
gini_index: اندازه گیری نابرابری بین توزیع ویژگی های برچسب. تقسیم بر روی یک ویژگی انتخابی منجر به کاهش متوسط شاخص جینی زیر مجموعههای حاصل میشود.
دقت: یک ویژگی برای تقسیم انتخاب می شود که دقت کل درخت را به حداکثر می رساند.
minimum_square: یک ویژگی برای تقسیم انتخاب می شود، که فاصله مجذور بین میانگین مقادیر در گره را با توجه به مقدار واقعی به حداقل می رساند.
maximal_depth
عمق یک درخت بسته به اندازه و ویژگی های ExampleSet متفاوت است. این پارامتر برای محدود کردن عمق درخت تصمیم استفاده می شود.
اگر مقدار آن روی ‘-1’ تنظیم شود، پارامتر عمق حداکثر هیچ محدودیتی برای عمق درخت قرار نمی دهد.
در این حالت درخت ساخته می شود تا زمانی که سایر معیارهای توقف برآورده شوند. اگر مقدار آن روی ‘1’ تنظیم شود، یک درخت با یک گره تولید می شود.
apply_pruning
مدل درخت تصمیم را می توان پس از نسل هرس کرد. در صورت بررسی، برخی از شاخه ها با توجه به پارامتر اطمینان با برگ جایگزین می شوند.
Confidence
این پارامتر سطح اطمینان مورد استفاده برای محاسبه خطای بدبینانه هرس را مشخص می کند.
application_prepruning
این پارامتر مشخص می کند که آیا در طول تولید مدل درخت تصمیم باید از معیارهای توقف بیشتر از عمق حداکثر استفاده شود. اگر بررسی شود، پارامترهای حداقل افزایش، حداقل اندازه برگ، حداقل اندازه برای تقسیم و تعداد جایگزین های پیش هرس به عنوان معیارهای توقف استفاده می شود.
minimal_gain
سود یک گره قبل از تقسیم آن محاسبه می شود. گره در صورتی تقسیم می شود که بهره آن از حداقل بهره بیشتر باشد. مقدار بالاتر حداقل بهره منجر به شکاف های کمتر و در نتیجه درخت کوچکتر می شود. مقدار بسیار بالا به طور کامل از تقسیم جلوگیری می کند و درختی با یک گره تولید می شود.
minimal_leaf_size
اندازه یک برگ تعداد نمونه های زیر مجموعه آن است. درخت به گونه ای تولید می شود که هر برگ حداقل دارای حداقل اندازه برگ از نمونه ها باشد.
minimal_size_for_split
اندازه یک گره تعداد نمونه های زیر مجموعه آن است. فقط گره هایی تقسیم می شوند که اندازه آنها بزرگتر یا مساوی با حداقل اندازه برای پارامتر تقسیم است.
number_of_prepruning_alternatives
هنگامی که از تقسیم با پیش هرس کردن در یک گره خاص جلوگیری می شود، این پارامتر تعداد گره های جایگزین آزمایش شده برای تقسیم را تنظیم می کند. زمانی رخ می دهد که پیش هرس موازی با فرآیند تولید درخت انجام می شود. این ممکن است از تقسیم در گره های خاص جلوگیری کند، زمانی که تقسیم در آن گره به قدرت تمایز کل درخت نمی افزاید. در چنین حالتی، گرههای جایگزین برای تقسیم کردن امتحان میشوند.
فرآیندهای آموزشی
آموزش یک مدل درخت تصمیم
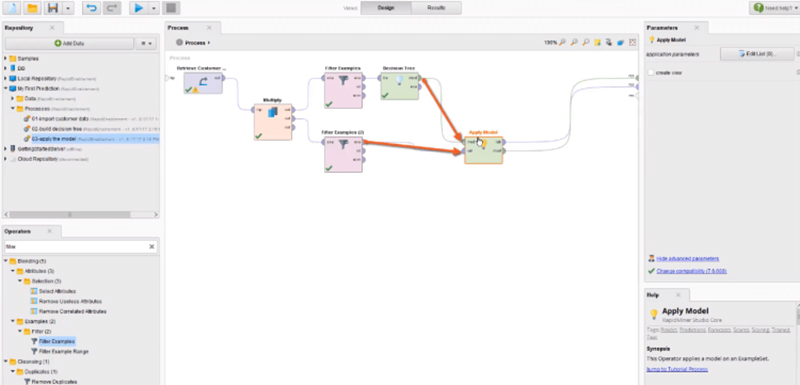
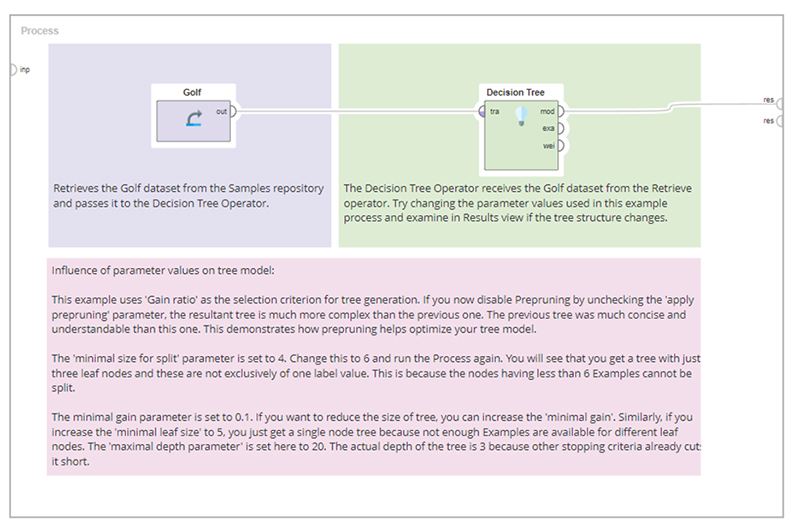
هدف: استودیوی RapidMiner یک مجموعه داده نمونه به نام “Golf” ارائه می کند. این شامل ویژگیهای مربوط به آب و هوا است، یعنی «چشمانداز»، «دما»، «رطوبت» و «باد». اینها ویژگی های مهمی برای تصمیم گیری در مورد اینکه آیا بازی می تواند بازی شود یا خیر هستند. هدف ما آموزش درخت تصمیم برای پیشبینی ویژگی «Play» است.
مجموعه داده “Golf” با استفاده از Retrieve Operator بازیابی می شود. این داده ها با اتصال پورت خروجی Retrieve به پورت ورودی Decision Tree Operator به اپراتور Decision Tree داده می شود. روی دکمه Run کلیک کنید. این مدل درخت تصمیم را آموزش می دهد و شما را به نمایش نتایج می برد، جایی که می توانید آن را به صورت گرافیکی و همچنین در توضیحات متنی بررسی کنید.
درخت نشان می دهد که هر گاه ویژگی «Outlook» دارای مقدار «پوشش» باشد، ویژگی «Play» مقدار «بله» را خواهد داشت.
اگر ویژگی «Outlook» دارای مقدار «باران» باشد، دو نتیجه ممکن است:
الف) اگر ویژگی “Wind” دارای مقدار “false” باشد، ویژگی “Play” دارای مقدار “بله” است.
ب) اگر صفت “Wind” دارای مقدار “true” باشد، ویژگی “Play” “no” است.
در نهایت، اگر ویژگی “Outlook” دارای مقدار “sunny” باشد، دوباره دو احتمال وجود دارد.
اگر مقدار ویژگی «رطوبت» کمتر یا برابر با 77.5 باشد، «بازی» «بله» است و اگر «رطوبت» بیشتر از 77.5 باشد، «نه» است.
در این مثال، گره برگ تنها به یکی از دو مقدار ممکن برای برچسب Attribute منتهی می شود. ویژگی «Play» یا «بله» یا «خیر» است، که نشان میدهد مدل درختی به خوبی با دادهها مطابقت دارد.
یک مدل درخت تصمیم را آموزش دهید و از آن برای پیش بینی نتیجه استفاده کنید
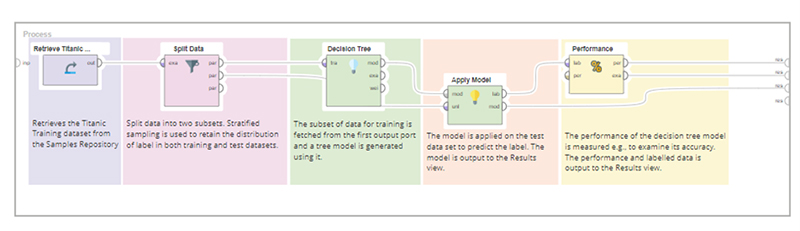
هدف: در این آموزش یک فرآیند تحلیل پیش بینی با استفاده از درخت تصمیم نشان داده شده است و نسبت به آموزش اول کمی پیشرفته است.
همچنین مفاهیم اساسی اما مهم مانند تقسیم مجموعه داده به دو پارتیشن را معرفی می کند. نیمه بزرگتر برای آموزش مدل درخت تصمیم و نیمه کوچکتر برای آزمایش آن استفاده می شود.
هدف ما این است که ببینیم مدل درختی چقدر میتواند سرنوشت مسافران را در مجموعه دادههای آزمایشی پیشبینی کند.
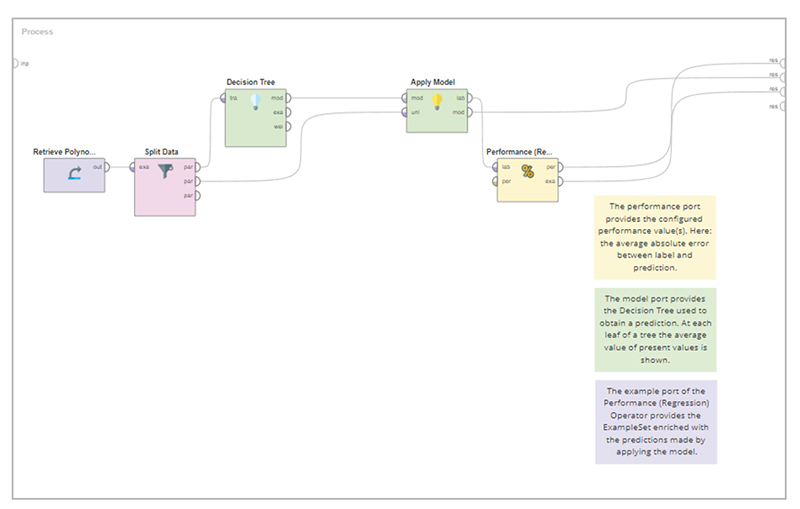
Regression
در این فرآیند آموزشی از درخت تصمیم برای رگرسیون استفاده می شود. مجموعه داده های “چند جمله ای” با ویژگی هدف عددی به عنوان یک برچسب استفاده می شود.
قبل از آموزش مدل، مجموعه داده ها به یک مجموعه تست و یک مجموعه آزمایشی تقسیم می شود. سپس مقادیر رگرسیون شده با مقادیر برچسب مقایسه میشوند تا یک معیار عملکرد با استفاده از عملگر عملکرد (رگرسیون) بدست آید.
دوره آموزشی هوش تجاری با Tableau »کلیک کنید« و هوش تجاری با Power BI »کلیک کنید« یک برنامه جامع است که بر توسعه مهارت در تجزیه و تحلیل دادهها، تجسم و گزارش سازی و گزارش دهی و دشبوردسازی با استفاده از این ابزارها تمرکز دارد.
سپاسگذاریم از وقتی که برای خواندن این مقاله گذاشتید
.
برای خرید لایسنس پاور بی ای Power BI کلیک کنید
.
برای مشاهده ویدیوهای آموزشی داده کاوی و هوش تجاری ما را در شبکه های اجتماعی دنبال کنید
Youtube Chanel :VISTA Data Mining ![]()
Aparat Chanel: VISTA Data Mining ![]()
Instagram Chanel: VISTA Data Mining ![]()
Telegram Chanel: VISTA Data Mining ![]()
Linkedin Chanel: VISTA Company ![]()