


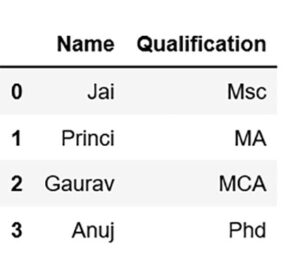
Python | Pandas DataFrame

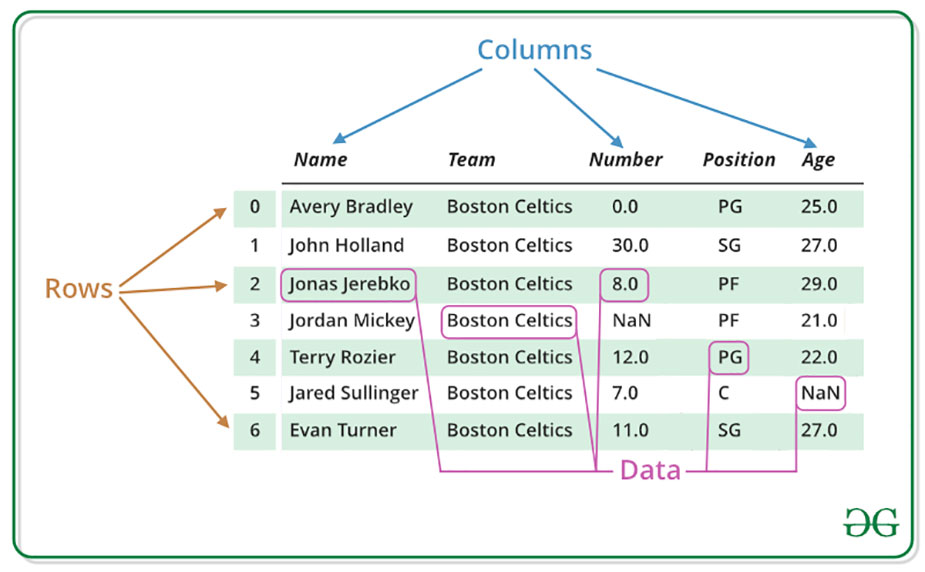
Pandas DataFrame ساختار داده ای جداولی دارای ابعاد قابل تغییر و ابعاد دو بعدی و دارای محورهای برچسب خورده (ردیف ها و ستون ها) است. فریم داده یک ساختار داده ای دو بعدی است ، یعنی داده ها به صورت جدول در سطرها و ستون ها تراز می شوند.
DataFrame از سه ملفه اصلی ، داده ها ، سطرها و ستون ها تشکیل شده است.
ما بینشی مختصر در مورد همه این عملیات اساسی خواهیم داشت که می تواند در Pandas DataFrame انجام شود:
- برخورد با ردیف ها و ستون ها
- نمایه سازی و انتخاب داده ها
- کار با داده های از دست رفته
- برخورد داده های تکرار روی سطرها و ستون ها
ایجاد Pandas DataFrame
در دنیای واقعی ، با بارگذاری مجموعه داده ها از حافظه موجود ، یک Pandas DataFrame ایجاد می شود ، فضای ذخیره سازی می تواند پایگاه داده SQL ، پرونده CSV و فایل اکسل باشد.
Pandas DataFrame را می توان از لیست ها ، فرهنگ لغت و از لیست فرهنگ لغت ها و غیره ایجاد کرد.
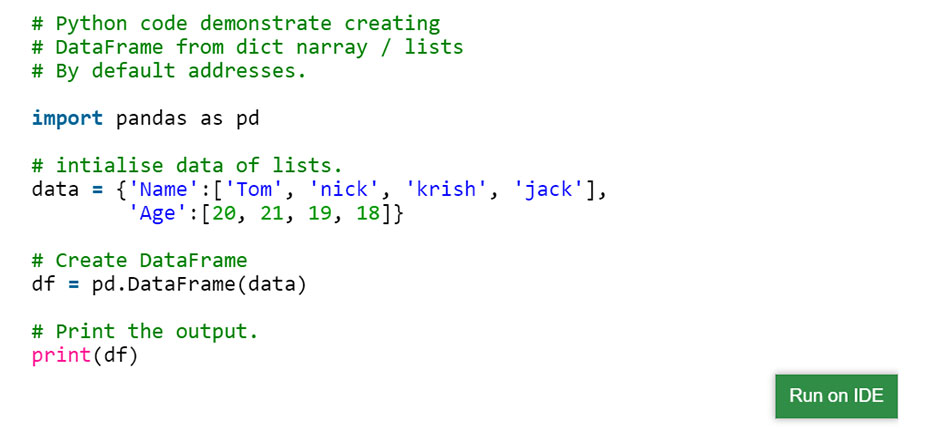
ایجاد یک لیست با استفاده از Pandas:
DataFrame را می توان با استفاده از یک لیست واحد یا لیستی از لیست ها ایجاد کرد.
استفاده از کتابخانه Pandas در پایتون – داده کاوی ویستا
Output:

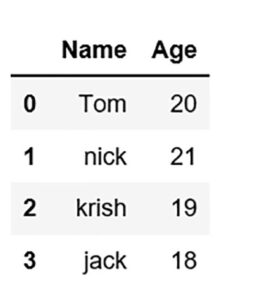
ایجاد DataFrame از dict of ndarray / لیست ها: برای ایجاد DataFrame از dict of narray / list ، تمام آرایه ها باید از یک طول باشند.
در صورت عبور از شاخص ، شاخص طول باید برابر با طول آرایه ها باشد.
اگر هیچ شاخصی وجود نداشته باشد ، به طور پیش فرض ، index محدوده (n) خواهد بود که n طول آرایه است.
Output:
برخورد با ردیف ها و ستون ها
فریم داده یک ساختار داده ای دو بعدی است ، یعنی داده ها به صورت جدول در سطرها و ستون ها تراز می شوند. ما می توانیم عملیات اساسی را روی سطرها / ستون ها مانند انتخاب ، حذف ، اضافه کردن و تغییر نام انجام دهیم.
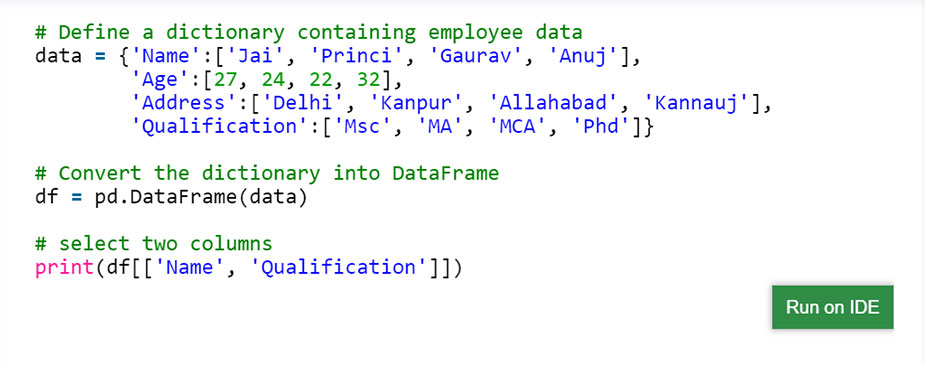
انتخاب ستون: برای انتخاب یک ستون در Pandas DataFrame ، می توانیم با فراخوانی ستون ها با نام ستون ها ، به آنها دسترسی پیدا کنیم.
Output:
انتخاب ردیف
Pandas یک روش منحصر به فرد برای بازیابی ردیف ها از یک قاب داده ارائه می دهد. از روش DataFrame.loc [] برای بازیابی ردیف ها از Pandas DataFrame استفاده می شود. همچنین می توان ردیف ها را با عبور مکان صحیح به یک تابع [] iloc انتخاب کرد.
توجه: در مثالهای زیر از پرونده nba.csv استفاده خواهیم کرد.
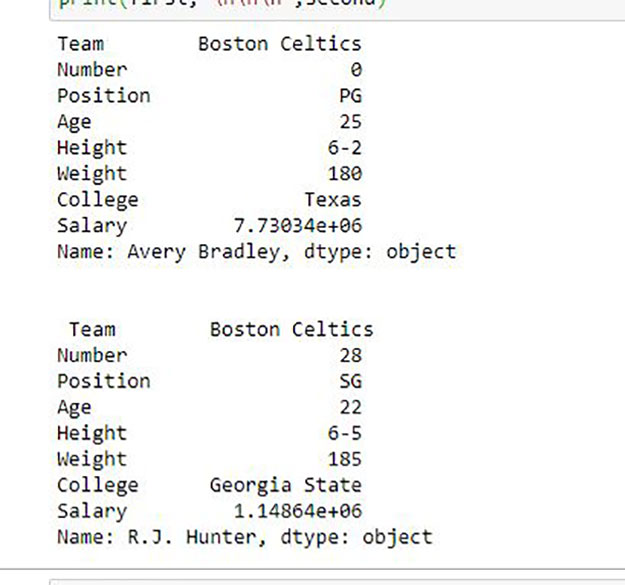
همانطور که در تصویر خروجی نشان داده شده است ، از آنجا که هر دو بار فقط یک پارامتر وجود داشت ، دو سری برگشت داده شد.
نمایه سازی (Indexing) و انتخاب داده ها
نمایه سازی در Pandas به معنی انتخاب ساده سطرها و ستون های خاص داده از DataFrame است. Indexing می تواند به معنای انتخاب تمام ردیف ها و برخی از ستون ها ، برخی از ردیف ها و همه ستون ها یا برخی از هر یک از ردیف ها و ستون ها باشد. نمایه سازی همچنین می تواند به عنوان Subset Selection شناخته شود.
نمایه سازی یک Dataframe با استفاده از عملگر نمایه سازی []
اپراتور نمایه سازی برای اشاره به براکت های مربع زیر یک شی استفاده می شود.
نمایه های .loc و .iloc نیز از اپراتور نمایه سازی برای انتخاب استفاده می کنند. در این اپراتور نمایه سازی به df []مراجعه کنید.
انتخاب یک ستون
به منظور انتخاب یک ستون ، ما به راحتی نام ستون را در داخل براکت قرار می دهیم.
Output:
نمایه سازی یک DataFrame با استفاده از .loc []
این عملکرد داده ها را با برچسب سطرها و ستون ها انتخاب می کند. نمایه کننده df.loc داده ها را به طریقی متفاوت از عملگر نمایه سازی انتخاب می کند. این می تواند زیر مجموعه های ردیف یا ستون را انتخاب کند. همچنین می تواند به طور همزمان زیر مجموعه های ردیف و ستون را انتخاب کند.
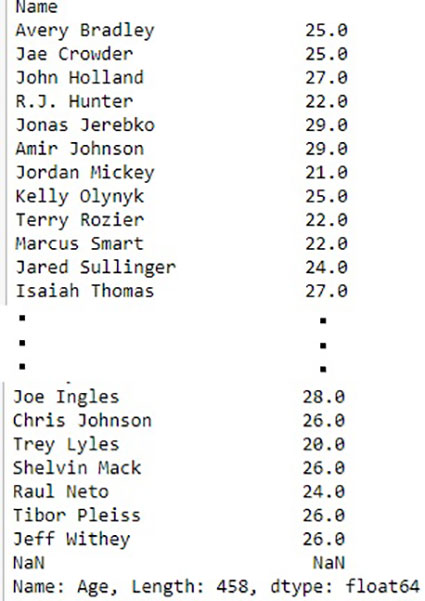
انتخاب یک ردیف واحد
به منظور انتخاب یک ردیف با استفاده از .loc [] ، یک برچسب ردیف واحد را در یک تابع .loc قرار می دهیم.
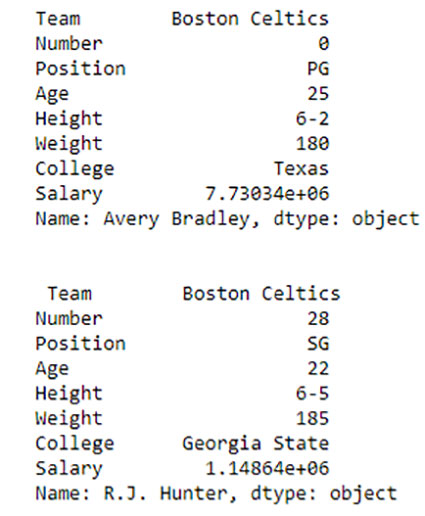
Output:
همانطور که در تصویر خروجی نشان داده شده است ، از آنجا که هر دو بار فقط یک پارامتر وجود داشت ، دو سری برگشت داده شد.
نمایه سازی DataFrame با استفاده از .iloc []
این عملکرد به ما امکان می دهد ردیف ها و ستون ها را براساس موقعیت بازیابی کنیم. برای انجام این کار ، باید موقعیت های ردیف مورد نظر و ستون هایی را که می خواهیم نیز مشخص کنیم. نمایه کننده df.iloc شباهت زیادی به df.loc دارد اما فقط از مکانهای عدد صحیح برای انتخاب خود استفاده می کند.
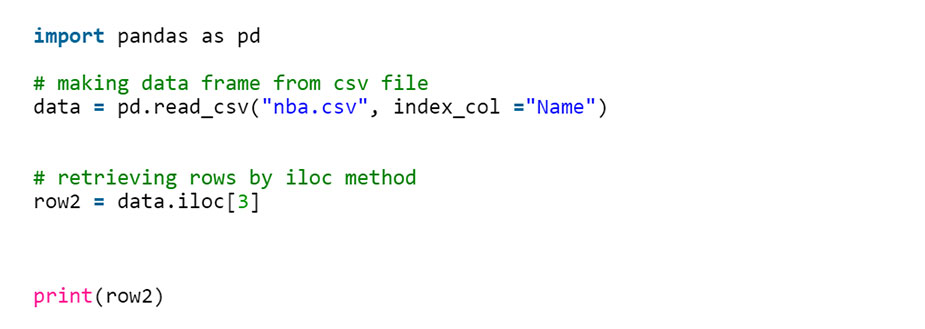
انتخاب یک ردیف واحد
به منظور انتخاب یک ردیف واحد با استفاده از .iloc [] ، می توانیم یک عدد صحیح را به تابع .iloc [] منتقل کنیم.
Output:

کار با داده های از دست رفته
وقتی اطلاعاتی برای یک یا چند مورد یا برای یک واحد کامل ارائه نشود ، داده های گمشده ممکن است رخ دهد. Missing Data یک مشکل بسیار بزرگ در سناریوی زندگی واقعی است. Data Missing همچنین می تواند به عنوان مقادیر NA (موجود نیست) در Pandas باشد.
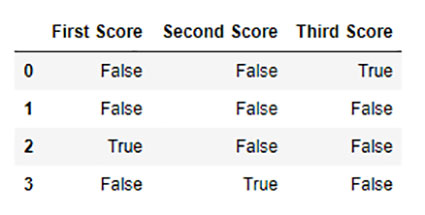
بررسی مقادیر از دست رفته با استفاده از isnull () و notnull ()
به منظور بررسی مقادیر از دست رفته در Pandas DataFrame ، از یک تابع isnull () و notnull () استفاده می کنیم. هر دو عملکرد در بررسی اینکه Na یک مقدار است یا خیر کمک می کند. این تابع همچنین می تواند در سری Pandas به منظور یافتن مقادیر صفر در یک سری استفاده شود.
Output:
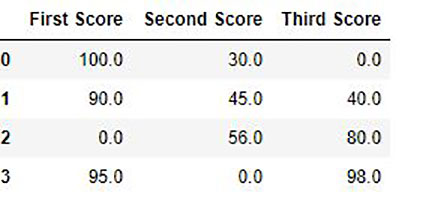
پر کردن مقادیر از دست رفته با استفاده از fillna () ، change () و interplates ()
به منظور پر کردن مقادیر خالی در مجموعه داده ها ، ما از تابع fillna () ، () جایگزین () و interpolate () استفاده می کنیم که این تابع مقادیر NaN را با مقداری از ارزش خود تعویض می کنند. همه این عملکردها به پر کردن مقادیر خالی در مجموعه داده های DataFrame کمک می کنند.
تابع () اینترپلات اساساً برای پر کردن مقادیر NA در چارچوب داده مورد استفاده قرار می گیرد اما از تکنیک مختلف درون یابی برای پر کردن مقادیر از دست رفته به جای رمزگذاری صحیح مقدار استفاده می کند.
Output:
حذف مقادیر از دست رفته با استفاده از dropna ()
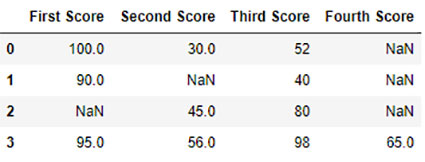
به منظور انداختن مقادیر خالی از یک فریم داده ، ما از تابع dropna () به روشهای مختلف از ردیفها / ستونهای مجموعه داده با مقادیر Null استفاده می کنیم.
Output:
دوره آموزشی زبان برنامه نویسی پایتون »کلیک کنید» یک برنامه جامع است که بر توسعه سریع نرمافزارهای کاربردی، برنامهنویسی شیگرا و کاربری ماژول و…. با استفاده از ابزار Python تمرکز دارد.
سپاسگذاریم از وقتی که برای خواندن این مقاله گذاشتید
.
برای خرید لایسنس پاور بی ای Power BI کلیک کنید
.
برای مشاهده ویدیوهای آموزشی داده کاوی و هوش تجاری ما را در شبکه های اجتماعی دنبال کنید
Youtube Chanel :VISTA Data Mining ![]()
Aparat Chanel: VISTA Data Mining ![]()
Instagram Chanel: VISTA Data Mining ![]()
Telegram Chanel: VISTA Data Mining ![]()
Linkedin Chanel: VISTA Company ![]()







