


کاربرد داده کاوی برای تشخیص دروغ
بازداشت یک مجرم آسان است در حالی که بیرون آوردن حقیقت از او دشوار است. مجری قانون می تواند از تکنیک های استخراج معادن برای بررسی جرایم ، نظارت بر ارتباط مظنون به تروریست استفاده کند.
این پرونده شامل استخراج متن نیز می باشد. این فرایند به دنبال یافتن الگوهای معنی دار در داده ها است که معمولاً متن بدون ساختار است.
نمونه داده جمع آوری شده از تحقیقات قبلی مقایسه شده و مدلی برای تشخیص دروغ ایجاد می شود. با استفاده از این مدل می توان فرآیندها را با توجه به ضرورت ایجاد کرد.
کشف دروغ (یا فریب) برای بسیاری از جمله اجرای قانون و پرسنل امنیتی از اهمیت اساسی برخوردار است.
اگرچه این افراد ممکن است سعی کنند از روشهای مختلفی برای کشف فریب استفاده کنند ، تحقیقات قبلی به ما می گوید که این امر بدون کمک با موفقیت محقق نمی شود.
حجم گفتگوی متنی ، پیام فوری و پیام متنی و همچنین تعداد ارتباطات عملی مبتنی بر متن به سرعت در حال افزایش است. حتی ایمیل همچنان در حال استفاده است. امروزه برای بسیاری از شرکت ها ، ایمیل یک دارایی مهم است و از دست دادن این ابزار آنها را به بن بست می کشاند.
با رشد گسترده ارتباطات مبتنی بر متن ، افراد برای فریب از طریق ارتباطات رایانه ای نیز رشد می کنند و چنین فریب هایی می تواند نتایج فاجعه باری را به همراه داشته باشد
برای خرید لایسنس تبلو Tableau کلیک کنید
کاربرد داده کاوی برای تشخیص دروغ
مثال را در مورد دختر جوان کالیفرنیایی که فکر می کرد دوست پسرش دنیا فکر می کند ، در نظر بگیرید بهتر است با مردن خود ، او را به خودکشی سوق دهد. به نظر می رسد که فرستندگان پیام ها دختر نوجوان دیگری و مادر آن دختر هستند (کیفرخواست ، شوخی کنندگان اینترنتی را به اطلاع می رساند ، 2008).
مردم نسبت به برنامه های مالی متقلبانه فریب خورده اند ، کودکان در جلسات با شکارچیان مجعول شده اند ، و سواستفاده های هک مانند “فیشینگ” امنیت را به خطر انداخته است. چنین مواردی آسیب پذیری های مربوط به فریب متن و دستکاری اطلاعات را نشان می دهد.
متأسفانه ، بشر به طور کلی در انجام وظایف کشف فریب عملکرد ضعیفی دارد. این پدیده در ارتباطات مبتنی بر متن تشدید می شود.
بخش عمده ای از تحقیقات در زمینه کشف فریب (همچنین به عنوان ارزیابی اعتبار شناخته می شود) شامل جلسات حضوری و مصاحبه ها بوده است. با این وجود ، با رشد ارتباطات مبتنی بر متن ، تکنیک های شناسایی فریب مبتنی بر متن ضروری است.
تکنیک هایی برای موفقیت در فریب ، یا دروغ ، کاربردهای جهانی دارد. نیروی انتظامی می تواند از این ابزارها و فنون پشتیبانی برای تحقیق در مورد جرائم ، انجام غربالگری امنیتی در فرودگاه ها یا نظارت بر ارتباطات مظنون به تروریست استفاده کند.
متخصصان منابع انسانی ممکن است از ابزارهای تشخیص فریب برای غربالگری متقاضی استفاده کنند این ابزارها همچنین امکان کشف پیامهای تصویری برای کشف کلاهبرداری یا سایر اقدامات نادرست مرتکب شده توسط افسران نرخ بهره را دارند.
Data mining
کاربردهای بالقوه یک ابزار تشخیص فریب مبتنی بر متن و همچنین منابع بالقوه متن برای تجزیه و تحلیل ، بسیار گسترده است. جای تعجب نیست که یک مطالعه قبلی نشان داده است که همراهی و افزایش استفاده از ارتباطات متنی ، مانند ایمیل و پیام فوری ، تمایل به دروغ گفتن در این اشکال ارتباطی است (Hancock، Thom-Santelli، & Ritchie، 2004).
علاوه بر متن به صورت تایپ شده مانند ایمیل ، پیام فوری ، اسناد پردازش کلمه ، دستور فریب مبتنی بر متن را می توان در هر ارتباط کلامی که می تواند به صورت تایپ شده و الکترونیکی تولید شود ، اعمال شود.
به عنوان مثال ، همانطور که در این مطالعه انجام شد ، می توان اسناد دست نویس را رونویسی کرد. برای ضبط ارتباطات شفاهی از نرم افزار تشخیص صدا یا سایر ابزارهای رونویسی می توان استفاده کرد که سپس قابل ارزیابی است.
روش شناسی
این مطالعه بیانیه های شخصی مورد علاقه افراد درگیر در جرایم در پایگاه های نظامی را مورد تجزیه و تحلیل قرار میدهد.
در این اظهارات ، مظنونان و شاهدان ملزم هستند خاطرات خود را در مورد این واقعه به قول خودشان بنویسند. پرسنل اجرای قانون پایه (LE) داده های بایگانی را برای اظهاراتی جستجو کردند که می توانستند به طور قاطع صادق یا فریبنده باشند. این تصمیمات بر اساس شواهد تأیید کننده و تصمیمات موردی (یعنی نه فقط نظر شخصی پرسنل LE) گرفته شده است.
تعریف نهایی فریب به اطلاعات غیررسمی ارتباط عمدی متکی است ، بنابراین اظهاراتی که شخص مورد علاقه در یادآوری وقایع اشتباه کرده باشد برچسب فریبنده نبود.
روند استخراج ویژگی پیام
این روش خودكار مبتنی بر فریب مبتنی بر متن ، فرایندی است كه به عنوان استخراج ویژگی پیام (MFM) شناخته می شود. این فرایند به عناصر تکنیک های داده کاوی و متن کاوی متکی است. به طور سنتی ، داده کاوی متغیرهای طبقه ای یا عددی را برای یافتن الگوهای معنی دار در حجم زیادی از داده های ساختاری / جدولی تجزیه و تحلیل می کند.
متن کاوی همچنین به دنبال یافتن الگوهای معنادار در داده ها است ، اگرچه داده ها معمولاً به عنوان متن بدون ساختار سرچشمه می گیرند.
این متن باید قبل از تجزیه و تحلیل به برخی از قالب های ساختار یافته تبدیل شود. همانطور که در شکل زیر نشان داده شده است، هر دو تکنیک داده کاوی و متن کاوی با هم ترکیب می شوند. روند کلی با آماده سازی داده ها برای پردازش آغاز می شود. در اینجا ، گفته ها در ابتدا با دست نوشته شده بودند و هر یک باید به یک پرونده پردازش متن تبدیل می شدند.
بعد ، ویژگی ها یا نشانه ها مشخص شدند. پیش از این بیش از 30 ویژگی متفاوت زبانی شناسایی شده بود که ممکن است به تمایز بین سخنرانان فریبنده حقیقت لقب دهد. این نشانه ها از نظریه های مورد استفاده برای مطالعه فریب سرچشمه می گیرد ، از جمله: نظارت بر واقعیت ، نظریه فریب بین صوتی ، نظریه دستکاری اطلاعات و چشم انداز خود ارائه فریب.
نظارت بر واقعیت در ابتدا به عنوان یک تئوری فریب توسعه نیافته بود ، اما به این زمینه گسترش یافته است. واقعیت نظریه نظارت بر واقعیت ها از خاطرات مبتنی بر تجربیات واقعی در مقابل خاطرات ساخته شده از بعد مختلف است .
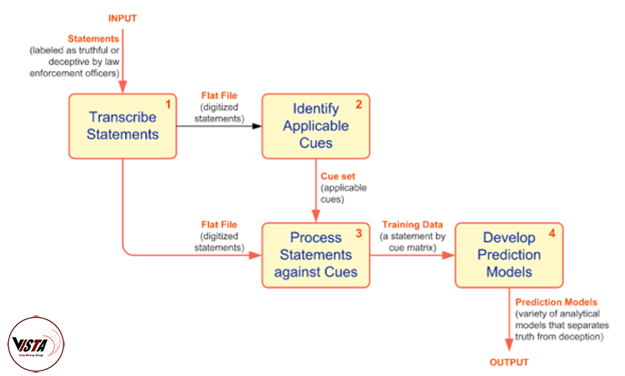
انتخاب ویژگی
یکی از رایج ترین وظایف در این نوع مطالعه پیش بینی داده ها پیش بینی ، انتخاب مناسب ترین ویژگی ها (به عنوان مثال نشانه ها) از لیست طولانی نامزدها است.
این امر به ویژه هنگامی صادق است که اندازه نمونه داده (تعداد اظهارات شخص مورد نظر در این مطالعه) نسبتاً کم باشد. الگوریتم انتخاب ویژگی مورد استفاده در این مطالعه برای هر ویژگی را محاسبه می کند.
ویژگی های مداوم ، الگوریتم محدوده مقادیر موجود در هر یک از پیش بینی های را تقسیم می کند (10 بازه معمولاً به عنوان پیش فرض استفاده می شود ؛ برای “تنظیم دقیق” حساسیت الگوریتم به انواع مختلف روابط یکنواخت و / یا غیر یکنواخت ، این تغییر یافته).
به هر حال پیش بینی کننده های طبقه بندی تغییر شکل نمی دهند. این الگوریتم انتخاب ویژگی هیچ نوع یا شکل خاصی از رابطه بین پیش بینی کننده ها و متغیرهای وابسته (کلاس) مورد نظر را در نظر نمی گیرد.
درعوض ، از یک “مفهوم رابطه” به طور کلی استفاده می کند در حالی که پیش بینی ها را یکی یکی برای مشکلات طبقه بندی غربال می کند.
نتایج مجدد الگوریتم انتخاب ویژگی مبتنی بر آمار را نشان می دهد.
از 31 نشانه ، 13 ویژگی برتر در تلاش برای توسعه مجدد گنجانده شده است. افت قابل توجه در مقدار مربع مجذور بعد از ویژگی سیزدهم نشان می دهد که آنهایی که باقی مانده اند وقتی در برابر تأثیر پیچیدگی آنها نسبت به مدل وزن می شوند ، بازده کافی ندارند.
مدل های تشخیص
در این مطالعه ، ما از چهار روش داده کاوی به همراه روش گروه مبتنی بر همجوشی اطلاعات استفاده کردیم:
- شبکه های عصبی مصنوعی
- درختان تصمیم گیری
- رگرسیون لجستیک
- تلفیق اطلاعات
سه مورد اول مسلماً مشهورترین روشهای مورد استفاده در طیف وسیعی از مطالعات کاربردی داده کاوی هستند و از این رو در اینجا انتخاب می شوند تا مبنایی برای دقت و همچنین یک نقطه مقایسه با مطالعات قبلی منتشر کنند. آنچه در زیر می آید ، شرح مختصری از مدلهای کشف این است.
۱- شبکه های عصبی مصنوعی
شبکه های عصبی مصنوعی (ANN) معمولاً به عنوان تکنیک های تحلیلی الهام گرفته از منطق زیست شناختی شناخته می شوند ، که می توانند توابع غیر خطی پیچیده خارجی را مدل سازی کنند (هایکین ، 2008). در این مطالعه ما از یک معماری معروف شبکه عصبی به نام Multi-LayerPerceptron (MLP) با الگوریتم یادگیری انتشار مجدد استفاده کردیم. MLP اساساً مجموعه ای از سلولهای عصبی غیرخطی است که در یک ساختار چند لایه به جلو خورده سازمان یافته و به یکدیگر متصل می شوند.
۲- درختان تصمیم
درختان تصمیم ، همانطور که از نام آن پیداست ، تکنیکی است که بطور مکرر مشاهدات را در شاخه ها از هم جدا می کند تا درختی را به منظور بهبود دقت تشخیص ایجاد کند.
با انجام این کار ، الگوریتم های ریاضی مختلف (به عنوان مثال ، افزایش اطلاعات مبتنی بر آنتروپی ، شاخص جینی و غیره) برای شناسایی یک متغیر و آستانه متناظر برای متغیر استفاده می شود که مجموعه مشاهدات را به دو گروه یا گروه های دیگر تقسیم می کند.
این مرحله در هر گره برگ تکرار می شود تا زمانی که درخت کامل ساخته شود. مدل درخت تصمیم خاص مورد استفاده در اینجا C&RT بود.
۳- رگرسیون لجستیک
رگرسیون لجستیک تعمیم رگرسیون خطی است. در درجه اول برای پیش بینی تغییرات وابسته باینری یا چند طبقه استفاده می شود. از آنجا که متغیر پاسخ گسسته است ، مستقیماً با رگرسیون خطی قابل اصلاح نیست.
بنابراین ، به جای پیش بینی یک تخمین نقطه از واقعه ، این مدل را برای پیش بینی شانس وقوع آن می سازد. در یک مسئله دو کلاسه ، احتمال 50٪ بالاتر از این به این معنی است که پرونده در غیر این صورت به کلاس تعیین شده “1” و “0” اختصاص داده می شود.
در حالی که رگرسیون لجستیک ابزاری بسیار قدرتمند برای مدل سازی است ، فرض می کند که متغیر پاسخ (شانس thelog ، نه خود واقعه) در ضرایب متغیرهای قبل از دیکتوری خطی است. علاوه بر این ، مدلساز ، بر اساس تجربه خود یا تجزیه و تحلیل داده ها ، باید ورودی های مناسب را انتخاب کرده و رابطه عملکردی آنها با متغیر پاسخ را مشخص کند.
۴- تلفیق اطلاعات
روش های گروه مبتنی بر همجوشی اطلاعات از فرایند “هوشمندانه” “ترکیبی از اطلاعات (کشف در این مورد) ارائه شده توسط دو یا چند منبع اطلاعات (به عنوان مثال ، مدل های شناسایی) استفاده می کنند.
به عنوان مثال ، اگر گزاره ای توسط دو یا چند مدل از سه مدل منفرد استفاده شده در اینجا برچسب خورده باشد ، طبقه بندی آن به عنوان فریبنده طبقه بندی می شود ، در حالی که گزاره ای که فقط در یکی از مدل ها به عنوان فریبنده طبقه بندی شده باشد ، برچسب درستکاری دارد در حالی که بحث در مورد سطح پیچیدگی روشهای همجوشی در جریان است ، یک توافق عمومی وجود دارد که همجوشی (ترکیبات تشخیصی) معمولاً مدلهای دقیق تر و با قابلیت شناسایی بیشتری را تولید می کند.
دوره آموزشی هوش تجاری با Tableau »کلیک کنید« و هوش تجاری با Power BI »کلیک کنید« یک برنامه جامع است که بر توسعه مهارت در تجزیه و تحلیل دادهها، تجسم و گزارش سازی و گزارش دهی و دشبوردسازی با استفاده از این ابزارها تمرکز دارد.
سپاسگذاریم از وقتی که برای خواندن این مقاله گذاشتید
.
برای خرید لایسنس پاور بی ای Power BI کلیک کنید
.
برای مشاهده ویدیوهای آموزشی داده کاوی و هوش تجاری ما را در شبکه های اجتماعی دنبال کنید
Youtube Chanel :VISTA Data Mining ![]()
Aparat Chanel: VISTA Data Mining ![]()
Instagram Chanel: VISTA Data Mining ![]()
Telegram Chanel: VISTA Data Mining ![]()
Linkedin Chanel: VISTA Company ![]()






