


تجزیه و تحلیل آماری با زبان R یکی از بهترین اقداماتی است که آماردان، تحلیلگران داده و دانشمندان داده هنگام تجزیه و تحلیل داده های آماری انجام می دهند.
زبان R یک زبان برنامه نویسی منبع باز محبوب است که به طور گسترده از بسته های داخلی و بسته های خارجی برای تجزیه و تحلیل آماری پشتیبانی می کند. زبان R به طور بومی از محاسبات آماری پایه برای داده های اکتشافی و آمارهای پیشرفته برای تجزیه و تحلیل داده های پیش بینی شده پشتیبانی می کند. تجزیه و تحلیل آماری با «R» بخش مهمی از شناسایی الگوهای داده بر اساس قوانین آماری و محدودیت های تجاری است. با توجه به سادگی دستور R و انعطاف پذیری استفاده از بسته های پیشرفته. زبان R برای تجزیه و تحلیل آماری ترجیح داده می شود.
برای دانلود دوره آموزشی R پیشرفته کلیک کنید.

چگونه با زبان R تجزیه و تحلیل آماری انجام دهیم؟
حال اجازه دهید در مورد چگونگی انجام تجزیه و تحلیل آماری با زبان R صحبت کنیم.
- برای شروع با تجزیه و تحلیل داده های آماری با R، نیازمندی های تجاری برای یافتن الگوهای داده از داده های موجود باید روشن باشد.
- زبان R باید روی سیستم نصب شود
R را می توان در ویندوز، لینوکس و MAC OS X نصب کرد.
فایل قابل نصب برای R را می توان از https://cran.r-project.org/ دانلود کرد.
- در مرحله بعد، IDE مانند R Studio باید روی سیستم نصب شود.
R Studio پشتیبانی رابط کاربری گرافیکی را به همراه برخی از ویژگیهای آماده سازمانی مانند Syntax hiliting، اشکال زدایی، بستهها و مدیریت فضای کاری ارائه میکند.
- R Studio را می توانید از https://www.rstudio.com/ دانلود و نصب کنید.
پس از نصب استودیوی R، می توان مستقیماً از آن برای توسعه اسکریپت R استفاده کرد که روی نسخه نصب شده زبان R کار می کند.
- هنگامی که Environment آماده شد، مرحله بعدی وارد کردن مجموعه داده به فضای کاری R است.
به عنوان مثال، ما یک فایل csv. را برای تجزیه و تحلیل آماری به استودیوی R وارد می کنیم. ما یک مجموعه داده منبع باز را از https://www.kaggle.com/ برای این نمایش دانلود خواهیم کرد. فایل داده ای که استفاده خواهیم کرد «cbb.csv» است که مجموعه داده بسکتبال کالج است،
برای خرید لایسنس تبلو Tableau کلیک کنید
رویکرد عملی تحلیل آماری با R
این بخش به صورت عملی از استودیوی R برای مجموعه داده بسکتبال کالج استفاده می کند.
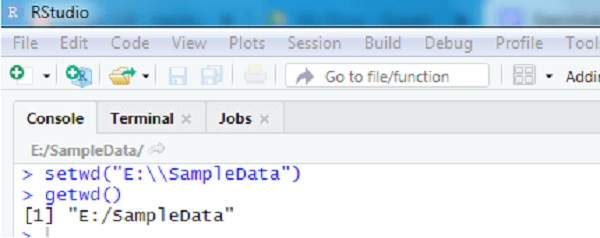
- اولین مرحله تنظیم دایرکتوری کاری است که به عنوان مکان ترجیحی برای خواندن و نوشتن مجموعه داده ها استفاده می شود.
- setwd() در R برای تنظیم دایرکتوری کاری استفاده می شود
- getwd() برای بررسی دایرکتوری کاری فعلی
- در ادامه تصویری از R Studio با توابع setwd() و getwd() مشاهده می کنید.
- سپس مجموعه دادهها را با استفاده از دستور csv() وارد میکند و به چارچوب دادهای به نام SampleData مطابق دستور زیر اختصاص میدهد.
- نمونه داده = csv (“cbb.csv”)
- برای بررسی صحیح مجموعه داده وارد شده و بررسی چند خط بالای داده از دستور head() در R استفاده کنید

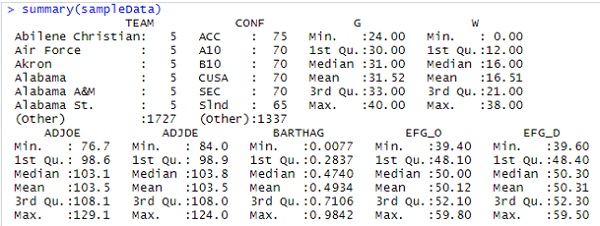
- در مرحله بعد، از دستور summary() برای انجام تحلیل های آماری پایه استفاده می کنیم که اطلاعات حداقل، حداکثر، میانگین، میانه و محدوده بین چارکی را در مورد مجموعه داده ها برای هر متغیر کمی نشان می دهد.
- خلاصه مجموعه داده های بسکتبال نشان می دهد که متغیر G دارای حداقل مقدار 24.00، حداکثر مقادیر 40.00، مقدار میانه 31.00 و مقدار میانگین 31.52 است.
- در مرحله بعد، به تحلیل داده های تک متغیره می پردازیم.
- فریم های داده R یک مرجع ذخیره داده کارآمد هستند،
- یک متغیر خاص را می توان از چارچوب داده با استفاده از نماد $ ارزیابی کرد
- به عنوان مثال برای مشاهده خلاصه آماری متغیر W از آن استفاده می کنیم
summary(sampleData$W)

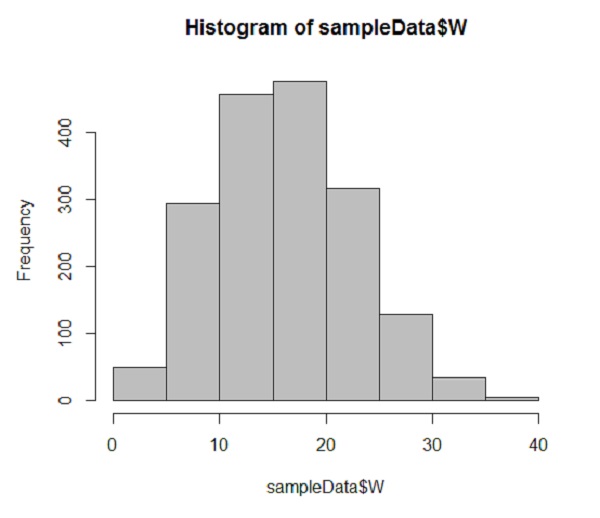
داده ها را می توان به صورت هیستوگرام با استفاده از Hist رسم کرد. دستور default() برای مشاهده توزیع کلی داده ها
hist.default(sampleData$W,col=’gray’)
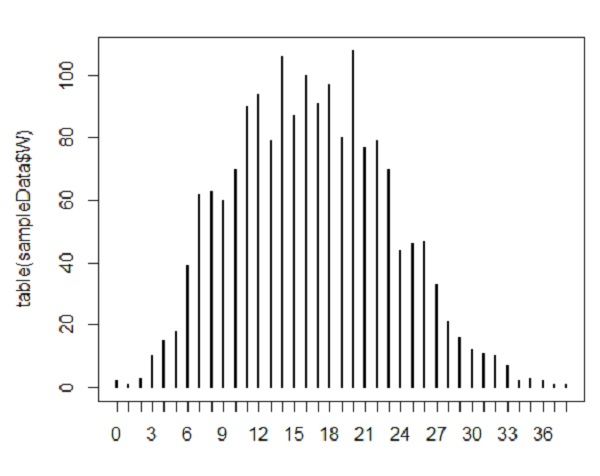
ما می توانیم از تابع Table برای ایجاد یک جدول فرکانس استفاده کنیم که تعداد فراوانی داده ها را در متغیر با استفاده از جدول (sampleData$W) نشان می دهد.
table(sampleData$W)

جدول فرکانس نشان می دهد که مقدار 20 دارای حداکثر فرکانس در داده ها است. این تابع هنگام انجام متغیرهای طبقه بندی آماری بسیار مفید است. همچنین، این جدول فرکانس را با استفاده از تابع نمودار در R با استفاده از > نشان می دهیم
plot(table(sampleData$W))
- در مرحله بعد، تحلیل آماری دو متغیره را با R مورد بحث قرار خواهیم داد
- این تحلیل آماری مقایسه بین دو متغیر موجود در آن مجموعه داده است.
- به شناسایی همبستگی و الگوهای بین دو متغیر کمک می کند.
- نماد “~” برای تجزیه و تحلیل دو متغیره در R استفاده می شود
- در این مثال، ما در حال ایجاد یک نمودار پراکندگی یا نمودار پراکندگی برای متغیر G و W با استفاده از آن هستیم
plot(sampleData$G~sampleData$W,col=’blue’)
این نمودار پراکندگی نموداری را برای تحلیل دو متغیره نشان می دهد
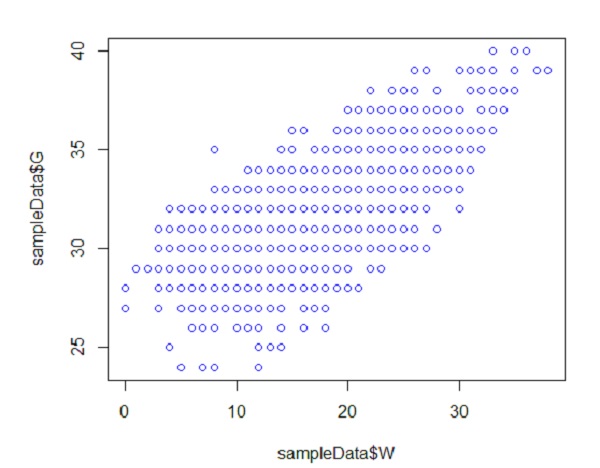
به غیر از نمودار پراکندگی، چندین توابع و نمودارهای دیگر مانند هیستوگرام، نمودار خطی و نمودار جعبه برای تجزیه و تحلیل دادههای دو متغیره استفاده میشوند.
- در مرحله بعد، ما در مورد آزمون t بحث خواهیم کرد که فرآیند آزمون فرضیه های آماری با استفاده از R است
- تابع t,test() در R برای پردازش t-test استفاده می شود
- برای آزمون t از داده های متغیر G از داده های نمونه قاب داده استفاده خواهیم کرد
test(sampleDat$G) – نحوی است که در کنسول R Studio اعمال خواهیم کرد.
- آزمون تی استنباط های آماری و فاصله اطمینان را به عنوان نتایج نشان می دهد.
p-value – مقدار احتمالی است که برای فرضیه صفر معنادار است. و مقدار درصد فاصله اطمینان است.
t.test(sampleData$G)

در این آزمون T، P-value <2.2e-16 و فاصله اطمینان 95٪ است. همچنین مقدار میانگین 31.52205 را نشان می دهد. این آزمون T نشان می دهد که فرضیه جایگزین در فرآیند آزمون فرضیه درست است.
اهمیت تجزیه و تحلیل آماری با زبان R
- Rیک زبان برنامه نویسی قابل اعتماد برای تجزیه و تحلیل آماری است.
- دارای طیف گسترده ای از پشتیبانی کتابخانه های آماری مانند آزمون T، رگرسیون خطی، رگرسیون لجستیک، تجزیه و تحلیل داده های سری زمانی است.
- R با ویژگی های تجسم داده های بسیار خوب ارائه می شود که از نمودارها با استفاده از بسته های گرافیکی مانند ggplot2 پشتیبانی می کند.
- این یک زبان برنامه نویسی است که به آماردانان و دانشمندان داده کمک می کند تا کدها را توسعه دهند و مدل های آماری فردی را برای تجزیه و تحلیل کارآمد داده ها آزمایش کنند.
- کد نوشته شده در R برای تجزیه و تحلیل آماری برای تفسیر آسان و قابل اشتراکگذاری برای سایر دارندگان پشته سازمان و همکاران است.
- R به عنوان یک زبان محبوب و دارای ساختار مناسب، چندین مؤلفه و کتابخانه های کد قابل استفاده مجدد برای شروع تجزیه و تحلیل آماری یک مجموعه داده ورودی دارد.
- زبان R شامل مجموعه دادههای داخلی مختلف برای یادگیری و ایجاد اثبات مفهوم قبل از استفاده از دادههای واقعی کسبوکار برای تجزیه و تحلیل آماری است.
نتیجه
این مرحله یکپارچه از پروژه های علم داده است. به دلیل پشتیبانی بومی از محاسبات آماری، پشتیبانی گسترده جامعه، آن را از رقبای خود مانند زبان پایتون، SAS، IBM SPSS Statistics، MATLAB، Minitab و Microsoft Excel منحصر به فرد می کند. تجزیه و تحلیل آماری با استفاده از R با ارتقاء نسخه در حال تکامل است.
دوره آموزشی زبان برنامه نویسی R »کلیک کنید» یک برنامه جامع است که بر توسعه محاسبات آماری و علم دادهها ، ایجاد اشکال گرافیکی و نمودارها و تحلیل سریهای زمانی، رگرسیون خطی و…. با استفاده از ابزار R تمرکز دارد.
سپاسگذاریم از وقتی که برای خواندن این مقاله گذاشتید
.
برای خرید لایسنس پاور بی ای Power BI کلیک کنید
.
برای مشاهده ویدیوهای آموزشی داده کاوی و هوش تجاری ما را در شبکه های اجتماعی دنبال کنید
Youtube Chanel :VISTA Data Mining ![]()
Aparat Chanel: VISTA Data Mining ![]()
Instagram Chanel: VISTA Data Mining ![]()
Telegram Chanel: VISTA Data Mining ![]()
Linkedin Chanel: VISTA Company ![]()







